Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion, SIMD, MIMD
Année 2002-2003
![]() Suite
N°5...
Suite
N°5...
11.8 AUTRES MACHINES PARALLÈLES
On les nomme plus correctement réseaux systoliques. Ils ont été imaginés pensant les années 1960. Ce sont des réseaux de processeurs plus ou moins étoffés. On dit de certains d'entre eux qu'ils appartiennent à la classe MISD. Chacun est connecté à 2, 4, rarement 6, exceptionnellement 8 voisins. Il sont soumis à la même horloge et fonctionnent de façon synchrone, soit pas à pas, soit par groupes d'instructions. En fonctionnement habituel, chaque processeur exécute une ou quelques instructions sur des données locales, puis transmet ces données à un ou des voisins. Ce fonctionnement les cantonne à un type de problème.
On y trouve tout l'éventail des processeurs :
Exemple
: La formule dite schéma de Horner.
y(n) = ((((anx + an-1)*x + an-2)*x + an-3)*x +... a1)*x + a0
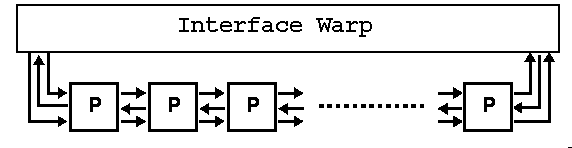
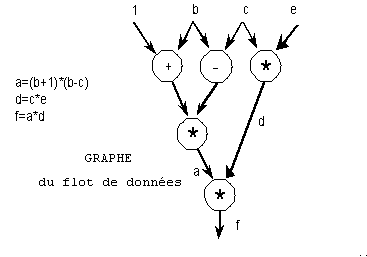
11.8.2 Machines à flots de données
L'idée de départ est de considérer la structure de dépendance entre les données elles-mêmes et non pas la structure de commande induite par la succession d'instructions. Un tel graphe de dépendance est figuré ci-dessous. La condition d'exécution d'une instruction n'est que la disponibilité de ses données.
Cette vision est la même que celle qui conduit à évaluer les possibilités d'anticipation entre instructions dans une fenêtre donnée. Elle avait été mise en uvre dans le CDC 6600. Dans les machines multiprocesseurs, alors forcément asymétriques, la demande d'exécution est émise par le séquenceur du processeur principal sous la forme d'un message qui contient l'opération, les adresses d'opérandes et l'adresse du processeur destinataire.
Ce message peut être :
En résumé, les opérations qui consistent à nommer un processeur ou un processus, descendent ici à des instructions ou des fonctions.
11.9 ÉTAT DU DÉVELOPPEMENT DES SYSTÈMES PARALLÈLES
Les architectures symétriques ont un avantage majeur. Sous les réserves de :
On verra dans le chapitre 12 que ces réserves ne sont pas de pure forme. Réciproquement, le découpage des programmes étant fait pour une machine parallèle, le code obtenu pourra être réutilisé sur une machine série sans beaucoup de modifications. L'écriture de programmes corrects et efficaces doit néanmoins tenir compte du modèle de mémoire.
Ici, la communication est implicite. Elle est le résultat des opérations d'accès à la mémoire par instructions de lecture et d'écriture. Des miniprocessus qui communiquent par écriture et lecture de pointeurs réalisent les entrées et sorties par canaux.
De processus indépendants utilisent des portions communes des adresses du noyau du système. Souvent la zone de code est commune, les autres segments comme la pile et des données sont privés.
Dans un système fonctionnant en temps partagé, on augmentera la capacité de traitement en ajoutant des processeurs. Selon les ressources disponibles, chacun prendra en charge une ou plusieurs tranches de temps. Un modèle d'extension à un système multiprocesseur en cas de mémoire partagée est figuré ci-dessous.
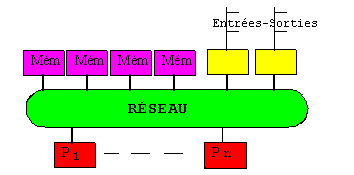
La relative lenteur des mémoires
conduit à les répartir en plusieurs bancs accessibles indépendamment.
Différents modes d'interconnexion
sont figurés ci-dessous :
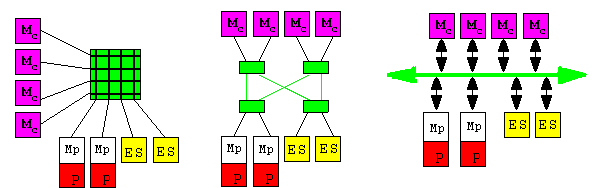
MATRICE D'INTERCONNEXION
RÉSEAU MULTINIVEAUX INTERCONNEXION
PAR BUS
(crossbar)
Mc : mémoire commune ou
partagée,
Mp : mémoire privée,
P : processeur,
ES : entrées et sorties.
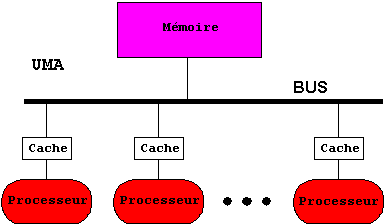
Le système d'interconnexion par bus est largement utilisé aujourd'hui bien que relativement lent. La capacité de débit du bus est le goulot d'étranglement. Chaque processeur a accès à la totalité du système d'adressage et chaque emplacement est donc équidistant de tous les processeurs. C'est pourquoi on nomme cette configuration MULTIPROCESSEUR SYMÉTRIQUE. On pourrait le nommer multiprocesseur isotrope ou encore à accès uniforme.
Exemple du système Pentium Pro :
Il s'agit de la carte mère quadriprocesseur Pentiumpro. Le MIU (memory interleaved unit) gère l'accès à plusieurs bancs de mémoire indépendants. Un câblage gère les caches.
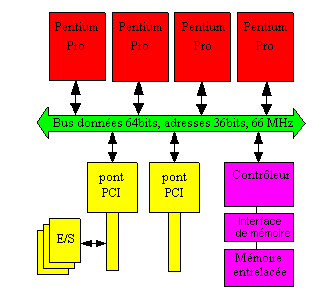
L'extensibilité ou évolutivité
(en anglo-saxon scalability) du système est limitée par la
bande passante, c'es-à-dire la capacité de transport du bus
unique ou éventuellement multiple comme dans le Sparc de Sun Microsystems.
L'existence de caches repousse cette limite au prix d'un travail supplémentaire
pour assurer la cohérence des caches pour des processus interdépendants.
Toutefois l'existence même de ces caches privés fait que,
si l'adressage reste commun, la mémoire ne l'est plus totalement
d'une part et que d'autre part la partie locale n'est pas uniquement consacrée
aux zones de données privées. Un système réel
relève rarement d'un modèle pur.
Dans le cas de tableaux d'interconnexion, la limitation vient du coût du tableau qui croît comme le carré du nombre de processeurs.
Les réalisations sont nombreuses et utilisées dans beaucoup de domaines, de deux à une centaine de processeurs.
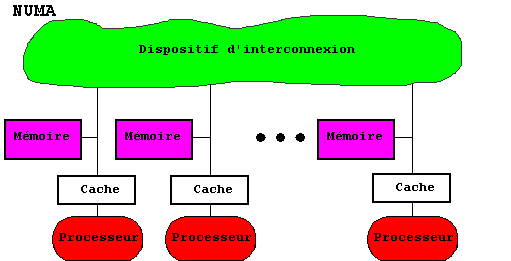
Les autres schémas où l'accès à la mémoire n'est pas uniforme sont nommés : mémoire à accès non uniforme NUMA (non uniform memory access). La mémoire commune peut y être répartie en bancs, les uns à accès uniforme, les autres attachés chacun à un processeur ce qui leur donne un temps d'accès le plus petit. Remarquons que les bancs de mémoire attachés à un processeur ne sont pas obligatoirement de la mémoire privée.
RÉSUMÉ : La communication par mémoire partagée est très largement utilisée. Elle relève d'un schéma de principe simple bâti autour de trois modes de communication. Les réalisations s'en écartent le plus souvent, soit parce que des ressources supplémentaires sont disponibles comme les caches, soit pour des motifs d'efficacité pour pallier la lenteur du bus unique ou du réseau ou le coût du tableau d'interconnexion. On trouvera une comparaison des perspectives comparées des machines symétriques, des machines en grappes et des NUMA.
11.10 MODÈLES MIXTES OU COMPOSITES
Dans ce qui précède, nous avons présenté les architectures dans leurs principes. Les réalisations sont encore plus mêlées.
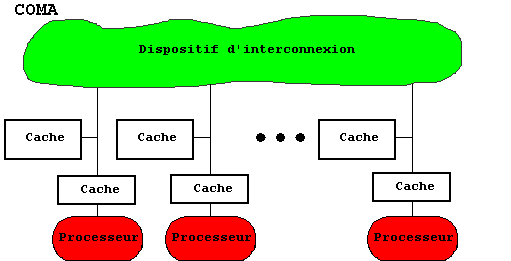
Un des plus grands parmi les processeurs massivement parallèles est le Cray T3E :
Les machines parallèles peuvent être comparées aux systèmes séquentiels comme suit.
Le fait fondamental est une bien plus grande liberté, à la fois du concepteur d'architectures que de l'utilisateur. Cette liberté est payée par un travail de maintien de cohérence et parfois de nouvelle rédaction des programmes.
En matière de langages de programmation, la maturité n'existe pas encore. Les modèles sont encore très divers et les programmes sont bâtis sur des modèles différents. Cette immaturité provient en grande part du fait que les modèles architecturaux ne sont pas figés.
Les méthodes d'évaluation que l'on sait arbitraires et peu efficaces en matière séquentielle, sont encore plus arbitraires et encore moins efficaces en matière parallèle.
L'analyse du problème, la recherche ou la création de l'algorithme adapté à l'architecture parallèle et au langage de programmation dont on dispose sont encore plus essentiels qu'en matière séquentielle.
La gestion du parallélisme par messages repose entièrement sur le langage et le système d'exploitation dont on dispose.
![]()
CE FICHIER N'A PAS DE QUESTIONNAIRE
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion,
SIMD, MIMD
Année 2002-2003
![]()
![]()