Architectures des systèmes informatiques
CHAPITRE 10
Parallélisme, taxinomies et classifications
Année 2002-2003
![]() Suite
N°2...
Suite
N°2...
«I
find digital computers of the present day to be very complicated and rather
poorly defined. As a result, it is usually impractical to reason logically
about their behaviour. Sometimes, the only way of finding out what they
will do is by experiment. Such experiments are certainly not mathematics.
Unfortunately, they are not even science, because it is impossible to generalise
from their results or to publish them for the benefit of other scientists.»
Déclaration de Tony Hoare au Boston Computer Museum
pour le dixième anniversaire de la revue Byte.
Je trouve
que les ordinateurs d'aujourd'hui sont très compliqués et
plutôt mal définis. En conséquence, il est normalement
impossible de raisonner logiquement sur leur comportement. Souvent, la
seule façon de savoir ce qu'ils vont faire est de faire l'essai.
Ce n'est certainement pas une attitude mathématique, hélas,
ce n'est même pas une science, car il est impossible de généraliser
ces résultats ou de publier ceux-ci pour éclairer les autres
scientifiques.
10.4
LES TAXINOMIES
10.4.1 Introduction
Quand on étudie l'architecture macroscopique des ordinateurs (ce qui est différent des performances), il est normal de vouloir comparer les machines entre elles sans avoir à comparer chaque détail. C'est pour cela que des classements des ordinateurs selon un petit nombre de leurs caractéristiques ont été imaginés. Un processus de classification ainsi que la définition et la constitution des classes est nommé taxinomie (en anglo-saxon taxonomy).
Une taxinomie réussie classe tous les items passés, présents et à venir.
Un exemple caricatural
de classification quelconque est celle qu'un empereur de Chine fit des
animaux :
«Les
animaux se divisent en:
a)
appartenant à l'Empereur;
b)
embaumés;
c)
apprivoisés;
d)
cochons de lait;
e)
sirènes;
f)
fabuleux;
g)
chiens en liberté;
h)
inclus dans la présente classification;
i)
qui s'agitent comme des fous;
j)
innombrables;
k)
dessinés avec un pinceau très fin en poils de chameau;
l)
et cætera;
m)
qui viennent de casser la cruche;
n)
qui de loin semblent des mouches»
(Cité
par Foucault, Les Mots et les Choses, Gallimard, 1966)
Deux exemples bien construits sont donnés dans l'annexe asi0018 relatifs aux entrées et sortie.
Choisir les bons caractères de classement n'est pas une activité de pure forme, il y faut vision prospective, profondeur de réflexion et chance.
Vision prospective car les caractéristiques significatives changent au cours du temps. Ce qui est considéré comme important aujourd'hui peut être dépassé par des développements et des innovations.
Profondeur de réflexion car une caractéristique peut devenir commune à tous les objets. Le critère devient alors inopérant. À l'opposé, une caractéristique abandonnée ne servira plus à rien. Un contre exemple est celui du classement des circuits intégrés en SSI, MSI, LSI, VLSI; aujourd'hui, tous les circuits sont VLSI.
Chance en ce qu'il faut apprécier l'évolution des goûts, des moyens et des besoins des utilisateurs, et la faveur future de chaque caractère.
On juge les taxinomies à leur longévité. Celle des circuits intégrés sous les noms de SSI MSI LSI VLSI de nature quantitative, dans les années 1960 est abandonnée. Celle de Flynn pour les ordinateurs date de 1966, elle a les insuffisances que l'on va voir mais demeure la plus utilisée.
Une taxinomie des ordinateurs comme celle d'autres objets est utile dans les deux sens de la ressemblance et de la dissemblance.
La ressemblance est utile pour étendre une propriété établie pour une machine à une autre de la même classe.Un item doit appartenir sans ambiguïté à une classe (parfois nommée taxon) et une seule. En pratique, pour les ordinateurs, la variabilité, la dépendance du point de vue que l'on prend pour l'examiner, de la couche que l'on examine comme référence, ou encore des décisions de reconfiguration possibles, mettent souvent cet objectif hors de portée. Certaines machines ont été définies pour faire des recherches sur le parallélisme. Pour des motifs d'économie et pour atteindre une certaine généralité, la même machine peut alors fonctionner selon des modes très différents comme le C.mmp de l'université de Carnegie Mellon. Cette machine est inclassable en elle-même. Une difficulté supplémentaire survient quand la machine change de catégorie par les améliorations qu'elle reçoit.
La dissemblance fait que chacune sera bien distinguée d'une autre.
En pratique, une taxinomie doit être simple et la nomenclature de ses classes facile à retenir. Parmi toutes celles qui ont été proposées, la plus réussie est celle de Flynn. Les taxinomies de Handler, de Hockney et Jesshope, et celle de Shore ne sont pas simples. On en donne quelques détails dans la suite.
Elle a été publiée en 1966. Flynn caractérise la dynamique des instructions et des données et non la structure de la machine. Le mot flot désigne une séquence soit d'instructions soit de données traitée par l'ordinateur. Chacun des deux flots est alors soit unique soit multiple. Nous avons donc deux critères, indépendants comme il se doit, à deux modalités chacun. Ils produisent évidemment quatre classes.
SISD
Simple Instruction Simple Donnée
SIMD
Simple Instruction Multiple Donnée
MISD
Multiple Instruction Simple Donnée
MIMD
Multiple Instruction Multiple Donnée
Le mot simple n'appelle pas de commentaire, Flynn a expliqué le mot multiple en 1966 :
«Multiplicity
is taken as the maximum possible of simultaneous operations [instructions]
or operands [data] being in the same phase of execution at the most constrained
component of the organization.»
Par
multiplicité, on entend le nombre maximum d'opérations (instructions)
simultanées ou d'opérandes (données) simultanés
qui sont dans la même phase d'exécution dans le composant
le plus critique de l'organisation.
Remarque :
Un pipeline unique n'apporte
pas de multiplicité en ce sens, un pipeline multiple rend la machine
multi instruction selon Flynn.
10.4.2.1 La machine SISD
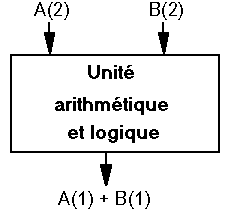
Une machine SISD est un ordinateur série conventionnel qui opère sur un flot d'instructions et un flot de données. On le nomme parfois ordinateur strictement de Neumann même s'il en diffère par des caches, des pipelines, etc.
Les instructions sont exécutées en séquence mais leurs manipulations peuvent se recouvrir partiellement dans un pipeline, tous les SISD sont ainsi aujourd'hui. Un SISD peut avoir plusieurs unités fonctionnelles, par exemple des coprocesseurs mathématiques, des unités vectorielles, des processeurs graphiques et d'entrées-sorties. Aussi longtemps que l'UAL est considérée comme un seul moyen de traitement, l'architecture reste SISD.
Une machine SISD :
10.4.2.2 La machine SIMD
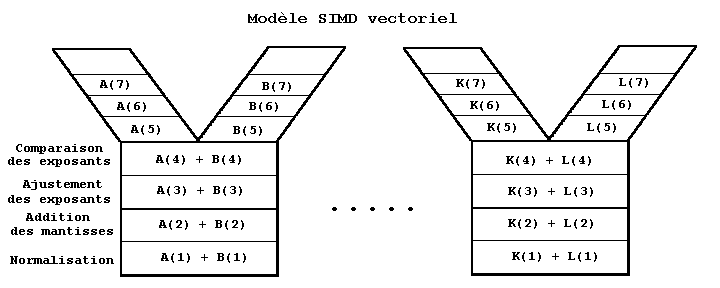
Un SIMD a deux UAL au moins sous les ordres d'une seule unité de commande. Celle-ci transmet les mêmes commandes simultanément à toutes les UAL. Flynn ne s'intéresse pas à la topologie des communications.
Une machine SIMD :
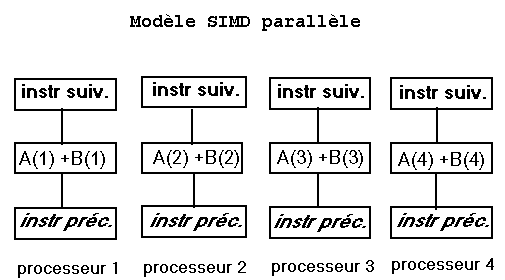
Avantages
La machine MISD a plusieurs processeurs. Elle exécute des flots d'instructions différents. Tous ces processus opèrent sur le même flot de données. Il y a deux façons de réaliser cela.
10.4.2.4 La machine MIMD
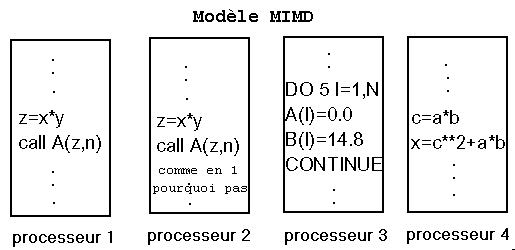
Les systèmes multiprocesseurs ou multi ordinateurs relèvent de cette classe. Plus brièvement ce sont tous ceux qui n'appartiennent pas à une classe précédente. Un MIMD a plusieurs éléments interconnectés, chacun a son unité de commande. Les processeurs travaillent sur des données propres avec leurs instructions propres. Les tâches exécutées par les différents processeurs commencent et finissent à des instants différents, le fonctionnement est asynchrone.
Une machine MIMD :
Avantages
Burroughs D825, Cray-2, S1, Cray
X-MP, HEP,
Pluribus, IBM 370/168 MP, Univac
1100/80, Tandem/16, IBM 3081/3084, C.m*,
BBN Butterfly, Meiko Computing
Surface (CS-1), FPS T/40000, iPSC.
MIMD réalisés en
mettant en parallèle des SISD :
Intel iPSC/860
IBM RS6000 cluster
MIMD réalisés en
mettant en parallèle des SIMD :
Cray 2, Cray X-MP, Cray Y-MP
à partir de Cray 1.
Le Cray T3E contient 256 processeurs.
La série des Fujitsu
VPP700 (machine achetée en 1999 par la Météorologie
nationale).
NEC SX-3 à partir de
Nec SX-2
10.4.2.5 Extensions de la taxinomie de Flynn qui apportent un premier aperçu sur la communication
Au vu de l'évolution des architectures, la taxinomie de Flynn a paru insuffisante. Des auteurs y ont ajouté des critères de subdivision des classes avec des succès inégaux.
Par des décompositions plus fines :
La classe SISD a été décomposée selon le nombre d'unités fonctionnelles :
En cas de processeurs multiples, les tâches qui leur sont affectées et qui travaillent sur le même problème, doivent être coordonnées afin que :
Avertissement : Les notions qui suivent sont reprises et développées dans le chapitre suivant.
La nature de ce moyen de communication induit le classement. Ce moyen peut être spatial ou temporel :
Les systèmes fondés
sur des bus relient tous les processeurs entre eux par la voie commune
qu'est le bus. Avec un réseau, chaque processeur n'est relié
directement qu'à des voisins immédiats. Les messages doivent
être acheminés (routage). Chaque processeur a sa propre mémoire
que l'on dit locale. Ils n'ont pas besoin de mémoire commune, ce
qui ne veut pas dire qu'il n'y en a jamais.
Ces architectures sont souvent
dites à couplage faible.
Le moyen temporel a deux variantes
Chaque processeur accède
à une même mémoire, ce qui les met en rivalité
ou compétition pour son usage (en anglo-saxon «contention»).
Si la mémoire unique
est commune à tous les processeurs, son adressage est continu.
Elle peut être en un seul bloc ou en plusieurs blocs, affectés
ou non à des processeurs.
Ces architectures sont souvent
dites à couplage fort.
Une autre dénomination
est
accès uniforme (UMA ou uniform access method).
Si la mémoire est toujours commune mais physiquement répartie (distribuée) entre les processeurs, chaque processeur accède sans retard à la partie de la mémoire qui lui est physiquement attachée. Il accède avec retard à un mot de mémoire attaché à un autre processeur. On parle alors d'accès non uniforme (NUMA ou non uniform access method).
10.4.2.6 Un peu de vocabulaire
La liste ci-dessous donne quelques abréviations utilisées pour des extensions de la taxinomie de Flynn.
SM-R mémoire commune
(shared memory) lectures multiples autorisées au même lieu
(multiple reads to same location allowed).
SM-W mémoire commune
(shared memory) écritures multiples autorisées au même
lieu (multiple writes to same location allowed).
SM-RW mémoire
commune (shared memory) lectures et écritures multiples autorisées
(both multiple reads and writes allowed).
SM mémoire commune
(shared memory) lectures et écritures multiples interdites (both
multiple reads and writes disallowed).
TC couplage fort (tightly
coupled).
LC couplage faible (loosely
coupled).
UC non couplé
(uncoupled).
Dans les ordinateurs qui autorisent les écritures simultanées en mémoire, SM-W et SM-RW, les conflits sont résolus de plusieurs façons :
Machines à couplage
fort (TC) : Burroughs D825, Cray-2, S1, Cray X-MP, HEP, Pluribus.
Machines à couplage
faible (LC) : IBM 370/168 MP, Univac 1100/80, Tandem/16, IBM 3081/3084.
Machines sans couplage
(UC) : Meiko Computing Surface, FPS T/40000.Certains auteurs, car l'unanimité
n'existe pas en informatique, considèrent les MIMD sans mémoire
commune comme une collection de monoprocesseurs SISD indépendants
et les nomment Multiple SISD ou MSISD. Toutefois, ces machines répondent
bien à la définition des MIMD et sont le plus souvent mises
dans cette classe.
![]()
CE FICHIER N'A PAS DE QUESTIONNAIRE
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 10
Parallélisme, taxinomies et classifications
Année 2002-2003
![]()
![]()