Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion, SIMD, MIMD
Année 2002-2003
![]() Suite
N°4...
Suite
N°4...
11.7.1 La question
L'écriture de programmes corrects et efficaces pour les systèmes à mémoire commune nécessite, au delà la partie proprement algorithmique d'application, de spécifier la sémantique des mémoires, grossièrement leur comportement. Comme il s'agit au fond de cohérence, on la nomme modèle de cohérence.
Deux exemples de comportement :
L'emploi d'un tampon d'écriture.
On utilise un tampon de stockage intermédiaire des résultats à écrire en mémoire pour éviter l'attente de l'écriture. La cohérence exige la vérification de la présence de la donnée dans la tampon pour chaque lecture. C'est relativement facile dans un monoprocesseur mais pas dans un multiprocesseur.
Les imbrications.
Avec deux processeurs
seulement et un bus unique, l'ordre de prise de commande du bus peut induire
des délais différents.
Soient deux processus
P1 et P2, P1 écrit A puis B, P2 lit A puis B.
La séquence réelle
peut être :
P1 écrit A,
P2 fait les deux lectures,
il lit donc une version de B qui n'est pas à jour.
Cette imbrication non maîtrisée est encore plus probable pour des mémoires gérées en mode EDO qui réservent le bus.
L'emploi de caches propres à chaque processeur rend la situation plus complexe car la même donnée peut être en plusieurs endroits et en plusieurs états. Considérons la séquence d'évènements qui suit où A et B sont deux processeurs et x une variable.
A lit x, causant une
défaut de cache, x = 45 est chargé dabs son cache.
B lit x, causant une
défaut de cache, x = 45 est chargé dabs son cache.
A écrit 12 dans
la variable x sans mettre à jour la mémoire.
B lit x de façon
réussie dans son cache, il obtient la valeur 45.
A vide x de son cache,
il écrit 12 en mémoire.
B lit x de façon
réussie dans son cache, il obtient toujours la valeur 45.
La définition
de Lamport [LAM79]
utilise la référence au modèle séquentiel.
Elle dit explicitement ce que le modèle de Neumann contient implicitement.
Elle est très proche de la cohérence
intuitive.
|
|
|
|
Il s'agit bien d'une définition et non d'une prescription opératoire. Selon la façon dont elle est obtenue, elle peut interdire certaines optimisations et réduire d'autant l'intérêt du multiprocesseur. C'est pourquoi beaucoup de multiprocesseurs l'appliquent sous une forme atténuée qui rend la situation encore moins simple.
Les effets
Le modèle de cohérence, intermédiaire entre le programmeur et le système, a trois effets :
Comment obtenir cette cohérence, il existe plusieurs modèles.
Le modèle le plus contraignant consiste en ce que :
L'ordre d'exécution du programme. On distingue différentes façons de procéder relatives à l'ordre entre une écriture et une lecture suivante, entre deux écritures, et enfin entre une lecture et les lectures ou écritures suivantes. Dans tous les cas, bien sur ces opérations portent sur des adresses différentes.
L'atomicité de l'écriture. Les distinctions sont fondées sur la manière dont le modèle autorise une lecture avant que toutes les autres copies aient été soit invalidées soit modifiées, c'est-à-dire avant que l'écriture soit visible de tous les autres processeurs.
En résumé, on peut avoir trois niveaux de cohérence :
11.7.2 Les solutions et les moyens
Quel que soit le modèle de mémoire, les mémoires et les caches propres aux autres processeurs doivent être à jour. En pratique cela signifie que :
Il faut :
Il existe divers moyens logiciels attachés au système d'exploitation ou au compilateur, nous n'en parlons pas. Les moyens proprement architecturaux sont le furet et le répertoire.
C'est un dispositif intégré dans chaque contrôleur de cache. On tourne ici le pré requis de connaître les emplacements des copies. Le support de chaque copie pourvoit à l'identification. Le contrôleur du cache dans lequel se produit une transaction qui pourrait produire une incohérence le signale à tous les autres caches. Il y a deux types de telles transactions :
Cette technique est simple à définir, complexe à mettre en uvre par les ressources matérielles qu'elle nécessite, consommatrice de temps de transport et génératrice de saturation du bus. Le rôle de l'arbitre du bus est important en ce qu'il attribue le bus aux requêtes.
Exemple : dans la machine Firefly de DEC, les informations données par le furet sont utilisées pour une politique mixte, compromis entre la performance et le maintien de la cohérence, dont l'intérêt est de moins utiliser le bus :
. la mise à jour
des données non communes est retardée;
. la mise à jour
immédiate des données communes est faite par diffusion des
écritures.
On trouvera le détail de cet algorithme dans [GRE96].
On revient au pré requis de connaissance des emplacements des copies. Les indications de présence des copies dans un ou plusieurs emplacements accessibles à tous sont stockées. Ce ou ces emplacements et leur contenu constituent le répertoire.
Le répertoire entretient l'inventaire de la présence et de l'état de toutes les lignes de données dans tous les caches. On peut dire qu'il est un résumé de tous les caches. La diffusion générale est alors inutile. Les mises à jour sont transmises aux seuls caches qui contiennent la donnée en cause. Le gain est double. D'une part le réseau de processeurs peut être hétérogène, d'autre part les volumes échangés sont moindres car la transmission n'est faite que si elle est nécessaire. Toutefois, on ne gagne rien en complexité de matériel car les solutions logicielles sont inefficaces et les réalisations matérielles sont aussi coûteuses que celles de furets. On dispose de plus de latitude pour augmenter le nombre de processeurs mais l'encombrement des accès au répertoire intervient alors.
Mécanisme du répertoire
Une entrée est créée dans le répertoire dès qu'une ligne (bloc en mémoire) est présente dans un cache au moins. Elle contient :
Le répertoire existe sous deux formes :
Le répertoire
central et le protocole centralisé.
Le répertoire est unique.
Le traitement est long, du fait de l'accès au répertoire
et de la lecture éventuelle de la copie dans le cache qui contient
la valeur la plus récente. Quand les caches sont groupés
en sous ensembles, on utilise parfois des sous répertoires.
Le
répertoire distribué
Les données de répertoire
sont réparties dans les caches. Chacun contient les informations
relatives à ses propres lignes et d'autres informations selon le
mécanisme de liaison entre les caches.
11.7.3 Une norme
La norme ANSI/IEEE 1596 définit le protocole d'un répertoire centralisé à liste doublement chaînée (avant et arrière). Chaque entrée a trois pointeurs, un vers l'entrée précédente, un vers l'entrée suivante dans la liste et un vers le dernier processeur cause de modification. Cette technique est bien adaptée à un grand réseau extensible d'interconnexion.
11.7.4 Une pratique
La description des états des lignes a fait l'objet d'un accord implicite quel que soit le protocole de manipulation. Cette description est connu sous l'acronyme MEPI (MESI en anglo-saxon) :
Modifié (modified),
la ligne a été modifiée;
Exclusif (exclusive),
ce cache contient la seule copie existant de la donnée. La mémoire
est valide;
Partagé c'est-à-dire
en commun (shared), une copie de cette ligne existe dans au moins un autre
cache, la copie en mémoire est invalide;
Invalide (invalid), la
ligne dans le cache est invalide.
Exemple de graphe d'état utilisant MEPI :
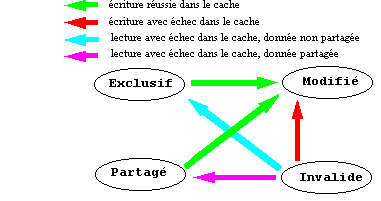
Deux autres protocoles répandus
existent nommés Illinois et Berkeley.
11.7.5 Un avertissement
Le lecteur aura remarqué que dans tous les développements précédents il n'a été question que de mémoire et de caches. Les questions de cohérence portent sur ces éléments. En toute rigueur, les moyens décrits garantissent la cohérence des contenus de ces composants de l'ordinateur.
On se rappelle les trois modèles principaux de fonctionnement selon la classification par opérandes :
Cette situation peut être critique pour les processeurs RISC qui ont un très grand nombre de registres utilisés comme blocs notes pour éviter des lectures et des écritures.
![]()
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion,
SIMD, MIMD
Année 2002-2003
![]()
![]()