Architectures des systèmes informatiques
CHAPITRE 14
Conclusions et perspectives sur les architectures parallèles
Année 2002-2003
![]()
Il n'est pas aisé de conclure sur un sujet en évolution rapide et multiforme. Ce chapitre ne porte que sur le thème du parallélisme externe explicite. Les conclusions et perspectives globales pour les architectures et les machines informatiques sont dans la conclusion générale.
14.1.1 Sur les modèles de programmation
En mémoire commune.
En mémoire commune
Les architectures simples n'existent pas car :
En passage de messages
Les architectures simples
existent.
La programmation est
compliquée.
14.1.3 Sur la cohérence
La complexité
du domaine est grande et les modèles nombreux. On trouvera dans
[IFT97]
une présentation détaillée de l'état de l'art
en matière de recherche sur les mémoires virtuelles communes,
les modèles de cohérence et les protocoles associés.
Le schéma suivant est
repris de leur publication aux seules fins d'illustration.
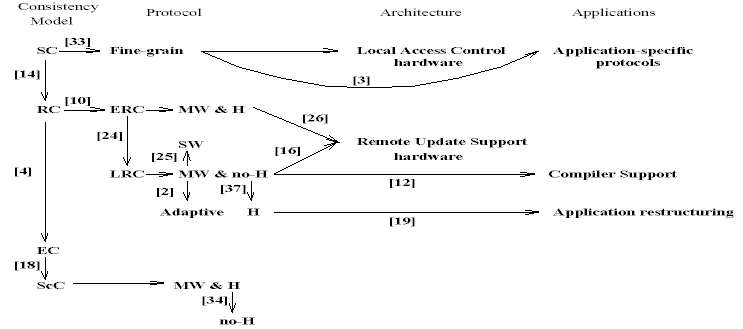
Les nombres entre crochets renvoient à la bibliographie de leur rapport. Ce sont les références des publications dans lesquelles la notion a été présentée pour la première fois.
La figure traite LRC et ERC comme des protocoles qui réalisent un modèle de cohérence RC, bien qu'ils puissent relever de modèles différents.
Signification des sigles :
Commençons par examiner l'importance du domaine des machines parallèles. Ce marché est une très belle hiérarchie :
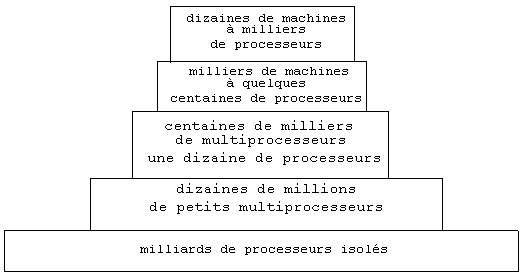
Ce marché a une demande solvable, nous pouvons donc nous intéresser aux constantes techniques.
Le rapport entre performances en Mflops et capacité de mémoire en mégaoctets est fondé sur les capacités d'intégration, il paraît relativement constant, entre 100 à 200. Il a toutes chances de demeurer à peu près constant pendant plusieurs années encore.
Il n'en est pas de même pour les capacités de transport. Certes des innovations récentes augmentent certaines capacités de transmission. On peut citer le bus IEEE 1394 pour les entrées et sorties, ATM pour les réseaux informatiques, les lignes d'abonnés numériques DSL (digital subscriber line) concurrents des RNIS sur le réseau téléphonique commuté. Toutefois, on ne constate pas le facteur 100 à 200 hors la fibre optique.
La tendance sera donc à une augmentation du nombre de niveaux de mémoire. Ceci demandera une forte amélioration des techniques d'anticipation, par cache et autres. Hélas, des caches hiérarchisés augmentent les prix et les temps morts ou temps d'attente (latency time); les prix faiblement mais les temps morts de façon importante. C'est crucial dans les multiprocesseurs.
La bonne tendance sera celle qui rendra le nombre d'échanges le plus petit possible, quelle que soit la nature de la technique. Mais il faut prendre en compte qu'une partie du besoin de communication est imposée par l'algorithme, l'architecture des machines n'y a pas de prise.
Le lecteur curieux ira chercher sur la toile de la documentation sur les architectures parallèles. Il trouvera d'innombrables références de recherches en cours, de très nombreux sites qui annoncent des enseignements, enseignements de DEA en France ou leurs équivalents ailleurs, et très peu de sites industriels.
L'évolution des systèmes parallèles inclut celle des machines classiques, autant sous l'angle électronique que par les conceptions architecturales. Comme dit plus haut, nous ne traitons ici que de ce qui est spécifique aux architectures parallèles.
Malgré leur petit nombre relatif, leur foisonnement et leur complexité, les machines parallèles font toujours l'objet de préjugés favorables. L'apparition de variantes cause des confusions nombreuses car le sens des mots y est encore plus mal fixé que dans les autres secteurs de l'informatique. Les évolutions de la technique font que les modèles changent. On examinera ici quelques futurs possibles pour les machines symétriques, pour les machines en grappe, pour une technique particulière basée sur les caches et pour les machines massivement parallèles. Un très bon texte de synthèse est dans [PAP98].
14.3.1 Architectures symétriques
On en a examiné leur principe de fonctionnement. Rappelons qu'à quelques différences près, on les nomme aussi SMP (symmetric multiprocessor) ou UMA (uniform memory access).
Rappelons aussi que l'efficacité et donc le succès de ce modèle sont dus à :
L'accès à la mémoire centrale, ressource commune, est le point critique en matière architecturale. D'une part les mots de la mémoire commune doivent être en protection réciproque pour interdire les mises à jour entrelacées, ce qui se fait par les verrous du système d'exploitation. D'autre part, plus nombreux et rapides sont les processeurs, plus grande est la charge de la liaison processeur à mémoire. Les bus classiques peinent à servir plus d'une dizaine de microprocesseurs. On essaie d'y échapper en introduisant des caches volumineux multiniveaux. La technique des caches a déjà été traitée. On bénéficie alors de la diminution du nombre des accès à la mémoire lente, pourvu que le processeur ne soit pas arrêté pendant le chargement du cache.
Ceci est favorable autant pour le débit des processeurs que pour la charge du bus de la mémoire commune. Cette réduction, on l'a déjà vu, est importante puisque 5% à 10% seulement des références provoquent un défaut de cache et donc un accès à la mémoire centrale. Les 90 à 95% autres sont disponibles dans le cache.
Ceci est défavorable dans la mesure où les caches peuvent contenir des copies de la même adresse de la mémoire centrale. Les contrôleurs de cache utilisent pour cela des furets pour identifier les autres copies des données et garantir la fraîcheur de la donnée utilisée. La contrepartie de cette surveillance et des mises à jour est un accroissement du trafic sur le bus de la mémoire. Cet accroissement est plus que proportionnel en raison de l'examen systématique des caches. Les répertoires ont des inconvénients comparables.
La conséquence de cette organisation est que le nombre de processeurs que l'on peut mettre en parallèle est fonction :
Une voie d'avenir est de répartir la mémoire en bancs à accès simultanés et de transporter les données par un commutateur. Le commutateur est utilisé dans le système Escala de Bull, mais les grands commutateurs sont chers.
Du point de vue de la fiabilité, il faut se convaincre qu'un système multiprocesseur symétrique ne garantit pas une fiabilité accrue par lui-même. Plusieurs de ses éléments sont en un seul exemplaire : bus, mémoire, entrées et sorties et le système d'exploitation. Un multiprocesseur symétrique n'est pas une machine où tous les éléments sont doublés.
Bien que ceci ne relève pas de ce cours, mentionnons que les systèmes d'exploitation doivent être décomposés en miniprocessus. Ceci n'est pas simple et reste coûteux dans la mesure où tous sont de conception ancienne et qu'on estime à dix ans le temps nécessaire pour atteindre une maturité convenable après refonte.
Enfin, relevons que ces architectures dites symétriques ne le sont plus physiquement dès que l'on introduit des caches locaux. Toutefois le programmeur voit encore une machine symétrique.
14.3.2 Architecture en grappes
Elle aussi, la grappe est simple concevoir et à réaliser. La machine C.mmp était une collection de PDP 11 munis d'un ordinateur frontal. Le fait de coupler des ordinateurs complets apporte une économie de conception et de fabrication par l'utilisation de produits de grande série. En revanche, le modèle de programmation doit être examiné soigneusement. Du simple au compliqué ou encore du moins couplé au plus couplé, on peut voir la grappe comme :
Examinons plus avant les grappes de performances. Les processus ou miniprocessus ont en général des données communes et fonctionnent comme suit :
Une première conclusion portant sur le seul fonctionnement interne est :
«le partage de disque»
(shared disk);
«le non partage»
(shared nothing).
Le partage de disque, dit aussi envoi de données (data shipping) consiste à autoriser les nuds de la grappe à accéder au stockage via une connexion au disque commun.
Le non partage du disque, dit aussi envoi des fonctions (function shipping), est la réciproque du précédent. Au lieu que chaque nud pourvu d'un processus demandant des données aille chercher ces données, on considère que des données sont disponibles ou éventuellement disponibles sur chaque nud. Le processus qui doit les «consommer» y est envoyé.
Le partage de disque équilibre mieux la charge d'exécution des processus au prix de l'interconnexion de disque ce qui est complexe pour un grands nombre de nuds et crée les mêmes goulots d'étranglement que les accès à une mémoire commune. Le partage est appliqué chez Oracle.
Dans le non partage, la gestion des accès au disque est bien maîtrisée, mais la répartition des processus reste à faire. Il faut que la demande de traitement soit équilibrée par rapport au choix préalable de répartition des accès aux données. Le non partage garantit que l'extension ultérieure du système ne sera pas limitée par les capacités d'entrées et sorties. Cette solution est actuellement préférée, on la trouve chez Tandem SQL/MX, Informix XPS et IBM DB2.
Revenons aux grappes proprement dites. Le constat a émergé dans les dernières années que le communication par message, quel que soit son intérêt est lente (relativement). Elle souffre semble-t-il de son ancienneté par des protocoles complexes ou mal adaptés, ressemblant ou dérivés des réseaux qui n'ont pas les mêmes contraintes de temps.
Une initiative de Microsoft, Intel et Compaq, annoncée au printemps 1997 est nommée VIA, pour virtual interface Architecture. Elle tend à normaliser les couches de bas niveau de passage des messages pour une interface du réseau du système SAN. Ses objectifs sont :
14.3.3 Autres modèles
Il s'agit d'abord du modèle NUMA et plus précisément de ce que l'on nomme parfois CC-NUMA pour «cache coherent non uniform access». On le trouve chez Bull et chez Silicon Graphics dans la machine Origin 2000 dont la figure suivante donne le principe.
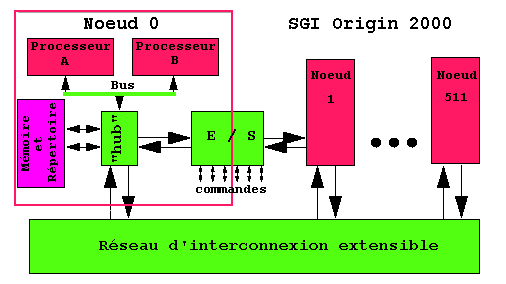
Tout commence comme s'il s'agissait d'une grappe de multiprocesseurs. Le système est constitué d'un assemblage de multiprocesseurs, aujourd'hui quatre, plus probablement dans les années à venir. Chacun d'eux a sa mémoire et ses E/S. Ils sont reliés par un réseau d'interconnexion. La différence par rapport aux grappes de multiprocesseurs vient de ce que l'interconnexion est utilisée pour unifier la mémoire totale. Elle n'est pas utilisée pour le passage des messages entre des nuds exécutant chacun sa propre copie du système d'exploitation.
L'adressage de la mémoire construite comme l'union des mémoires de tous les processeurs est uniforme. Chaque processeur de chaque groupe multiprocesseur adresse toute la mémoire globale. Il suffit d'un seul système d'exploitation résidant et d'un seul jeu de données. Une adresse de mémoire émise par un processus est dirigée selon le cas, vers la mémoire locale du processeur ou vers le système d'interconnexion, comme l'est une requête de mémoire virtuelle ou une requête au disque. La seule différence entre les accès est le temps de réponse. Le rapport entre le temps de réponse pour accéder à un mot non local par rapport à un mot local est le facteur NUMA, toujours supérieur à 3 et de préférence inférieur à 6. Il est bien sur possible, et cela figure dans les réalisations, de ménager un cache commun aux processeurs d'un groupe, comme de munir chaque processeur d'un cache local. La surveillance du réseau devra intégrer le maintien de la cohérence des données en cache dans les différents groupes. Une variante de ce système a été imaginée en combinant pagination et mémoire virtuelle avec l'adressage uniforme. Ce système est aussi nommé mémoire virtuelle partagée (SVM shared virtual memory)
En bref, pour le programmeur, un système CC-NUMA est un système symétrique avec nécessité de cohérence des caches. Cette question est compliquée par la pagination.
Il s'agit enfin du modèle COMA (cache-only memory access) qui n'est pas disponible sur le marché.
L'idée provient de la généralisation des caches et de la distinction entretenue, à tort ou à raison, entre mémoire centrale et cache. Dans le modèle COMA il n'y a plus de mémoire centrale mais seulement des niveaux de caches. La structure, sauf le changement de dénomination, d'un COMA est semblable à celle d'un CC-NUMA, des groupes de processeurs interconnectés.
La différence vient de ce que la mémoire locale dans les groupes de multiprocesseurs est traitée comme un cache. L'espoir est qu'ainsi la mémoire totale soit mieux utilisée et qu'on réduise le trafic sur le réseau.
La contrepartie est que l'on ne peut plus se contenter d'assembler des groupes de processeurs en l'état, en adaptant seulement leurs entrées et sorties au réseau. Les contrôleurs de mémoire des systèmes classiques ne sont plus utilisables.
Quelques mots sur le fond des choses.
Les progrès ne correspondent pas vraiment aux prévisions qui en avaient été faites. Les prévisions sur l'intégration à grande échelle des composants électroniques avaient fait construire l'échelonnement : SSI, MSI, LSI, VLSI. Les plus hautes classes VLSI puis UVLSI portaient sur quelques dizaines de milliers de composants. Nous en sommes à cinquante millions.
À l'opposé, le calcul parallèle qui n'est pas contraint par des considérations purement techniques a suscité de l'enthousiasme. Les résultats globaux ne sont pas à la hauteur de ces prévisions et des espoirs. Le motif principal est très probablement l'absence d'un modèle unique du calcul parallèle sur lequel tous les travaux auraient été concentrés. La situation inverse a fait le succès du modèle de Neumann pour le monoprocesseur. On voit de très nombreux, trop nombreux modèles, qui exigent chacun un son style de programmation propre.
![]()
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 14
Conclusions et perspectives sur les architectures
parallèles
Année 2002-2003
![]()
![]()