Architectures des systèmes informatiques
CHAPITRE 12
Parallélisation des programmes
Année 2002-2003
![]()
12.0 PRÉSENTATION
Ce chapitre n'est pas relatif aux architectures. Il est matière à lecture dans le cours d'architectures des systèmes informatiques. Il fait un premier lien avec la partie relative au traitement du signal dans le cours d'architectures parallèles. Il n'a pas de questionnaires, toutefois, pour le lecteur qui en ressent le besoin, des suggestions d'exercices sont faites çà et là.
Nous avons vu que les machines parallèles et les modèles associés sont très variés. Ceci demeure relativement abstrait tant qu'on ne passe pas à l'acte. Au delà de leur conception et de leur choix, l'acte est de programmer ces machines. Le présent chapitre a pour objet de faire saisir le processus qui, à partir d'un problème simple mène à des expressions parallèles. Une fois quelques schémas établis, on présentera les deux styles de programmation induits par les deux catégories, mémoire commune et communication par messages. Le lecteur est invité à considérer ce chapitre comme une illustration de l'usage que l'on peut faire de machines parallèles. Il ne traite pas des langages spécialisés que l'on apprend quand on est face à une machine particulière et à son environnement de programmation. Il ne traite pas non plus des méthodes de programmation existantes.
Ce chapitre contient :
12.1 une introduction;
12.2 la définition des
étapes;
12.3 un exemple
simple traité par étapes;
12.4 une conclusion.
Les architectures et les processeurs spécialisés sont choses intéressantes, le processus de parallélisation du travail à faire est tout aussi essentiel.
Cette parallélisation inclut :
La liste ci-dessus ne peut être suivie de façon rigoureuse dans de nombreux cas. Elle fait donc l'objet de modifications, de regroupements différents selon les auteurs. La terminologie non plus n'est pas fixée. Dans la suite, ce que nous nommons orchestration est parfois nommé agglomération.
Le lecteur est vivement invité à considérer les paragraphes suivants comme des possibles et non comme l'expression de méthodologies ou de méthodes affirmées. Le but de ce chapitre est à la fois d'illustrer des processus réalistes et de donner une claire idée de la complexité du domaine. En particulier, ne disposant pas d'une machine complètement spécifiée, le modèle de mémoire dont la nécessité était affirmée pour obtenir des programmes efficaces.
Dans ce qui suit :
Une tâche est une partie du travail total à réaliser. C'est la plus petite unité de travail mise en parallèle avec d'autres. Elle est exécutée sur un processeur unique. La parallélisation est faite entre les tâches. La définition des tâches est libre. Dans un programme séquentiel, les tâches sont apparentes sous la forme de procédures ou de modules; dans le domaine du temps réel, une tâche est le programme de gestion d'une interruption. Ces trois notions sont très différentes les unes des autres.
La taille des tâches détermine la granularité. Le grain fin (fine grain) qualifie des tâches petites, le grain grossier (coarse grain), des tâches dont les tailles sont relativement grandes. Cette qualification est arbitraire.
Un processus est une entité abstraite, celle qui mène les tâches à leur fin. En anglo-saxon, il est toujours nommé «process» dans le domaine séquentiel, et le plus souvent «thread» en matière simultanée. Le «thread» mènent au bout une tâche. Ceci le distingue du «process» qui mène au bout la totalité du travail à effectuer. Un programme parallélisé est composé de processus multiples. Chacun réalise un sous ensemble des tâches et doit pour cela coopérer avec les autres. Les tâches sont réparties entre les processus par une décision d'affectation. Tout au bout, les processus mènent les tâches à leur fin en les exécutant sur un processeur physique de la machine.
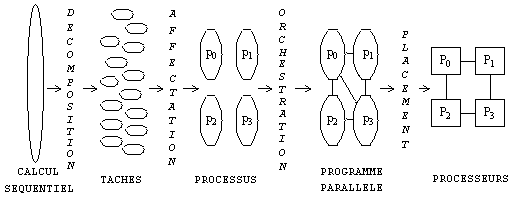
Nous présentons ci-après la suite de ces opérations sur un exemple qui sera détaillé au fur et à mesure du besoin.
Note : Les étapes ci-dessus ne relèvent pas d'une vérité démontrée. Selon les cas, une répartition différente peut-être utilisée. Par exemple selon la machine disponible ou encore selon le problème à traiter.
Le découpage en tâches, suivi par les autres étapes est une opération dont le principe existe ailleurs. Rappelons que dans une architecture superscalaire, le pipeline d'instructions est présentable avec :
En termes de performances, le paramètre essentiel est le nombre de processus, issu lui-même du nombre de tâches susceptibles de simultanéité.
Les évaluations de performances seront faites dans la suite en posant :
Exemple d'évaluation.
Soit une image carrée NxN à traiter comme suit :
Le temps séquentiel est 2N².
On suppose disposer de p processeurs. Comment s'y prendre, hors toute considération de communication ?
1ère solution.
On affecte N²/p points à
chaque processeur et on réalise la sommation de façon séquentielle.
Si toutes les opérations
sont faites en un même temps, le temps total consommé sera
N²/p pour la première partie, N² pour la seconde, soit
N²/p + N².
L'accélération
est alors 2N²/(N²+N²/p) soit 2p/(p+1).
L'accélération
est 2p/(p+1)
Elle ne dépend
pas du nombre de points,
elle a pour valeur limite
2 quand p croît indéfiniment.
2ème solution.
Décomposons la deuxième partie en deux phases. Dans la première chaque processeur fait les sommations relatives à ses données, dans la seconde, la sommation finale intervient. Les temps sont alors :
N²/p pour la première
partie;
N²/p pour la première
phase de la deuxième partie;
p pour la deuxième phase
de la deuxième partie, soit 2xN²/p +p.
L'accélération
est 2pN²/(2N²+p²).
Elle ne dépend
pas du nombre de points,
elle est tend à
être proportionnelle à p quand N devient grand devant p.
L'accélération possible ne dépend donc pas seulement du problème à traiter mais aussi de la façon dont on s'y prend.
12.2.2 L'affectation (ou répartition)
L'affectation groupe les tâches en processus.
Dans cette étape, le propos est de répartir équitablement la quantité de travail entre les processus, de limiter au mieux les communications entre les processus et de réduire le temps nécessaire à la gestion de cette répartition. Cette phase n'a pas non plus de règles fixes, c'est le règne des heuristiques plus ou moins bien adaptées. Fort heureusement, l'habitude prise depuis de nombreuses années de structurer les programmes séquentiels peut aider à faire l'affectation.
On distingue
12.2.3 L'orchestration
Le processus acquièrent une existence. Ils vont avoir besoin de mécanismes pour nommer les données, pour y accéder, pour faire des échanges entre processus et pour les synchroniser. L'architecture du système, le modèle de programmation et le langage de programmation jouent pour cela des rôles importants. Les choix à faire dépendent peu des deux étapes précédentes. Il se peut qu'à ce stade on doive revoir l'organisation des données. On y décide aussi de la taille des messages s'il y en a et de la synchronisation explicite ou implicite.
Les objectifs principaux de cette étape sont :
Il s'agit de placer les processus sur les processeurs. On prend en compte la topologie de communication de la machine. Il se peut que le système d'exploitation gère cette activité. Quand il le fait de façon dynamique, changeant de sa propre initiative la place de certains processus, il faut vérifier que l'on n'a pas des migrations nombreuses, coûteuses en temps. La solution est d'affecter (to pin en anglais, c'est-à-dire épingler) processus à processeur. Si le système d'exploitation ne fait pas le placement, seul ou avec le compilateur, le programmeur devra le faire avec les outils dont il dispose.
![]()
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 12
Parallélisation des programmes
Année 2002-2003
![]()
![]()