Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion,
SIMD, MIMD
Année 2002-2003


 Suite
N°3...
Suite
N°3...
11.6 PLACE ET INCIDENCE
DES CACHES
Les organisations précédentes
ne sont déjà pas simples. La présence quasi inévitable
de caches complique encore la chose. On présente ci-dessous quelques
types de réalisations incluant des caches.
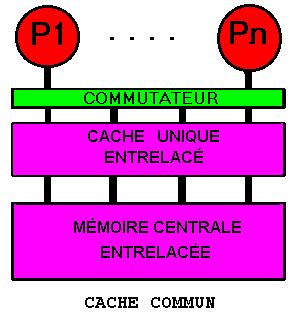
11.6.1 Cache commun
Système parfaitement
symétrique. Il contient un cache commun à tous les
processeurs. Il était utilisé dans les années 80 pour
des systèmes de 2 à 8 processeurs. Il reste d'actualité
pour des fabrications spécifiques, par exemple plusieurs processeurs
sur une même puce. Il n'autorise pas un grand nombre de processeurs
car, même si l'on met en place un mécanisme d'accès
simultané du processeur au cache et du cache à la mémoire
et que l'on applique la technique du cache non bloquant, ce cache et la
mémoire ont des bandes passantes limitées et le débit
du cache doit être considérable pour alimenter plusieurs processeurs.
Introduire des caches locaux dans chaque processeur apporte les avantages
et les inconvénients des schémas suivants.
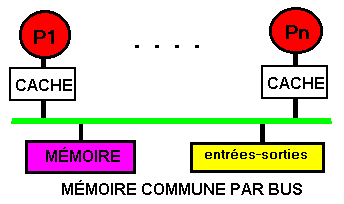
11.6.2 Cache privé
et bus
Système presque
symétrique.
L'accès à la mémoire est fait via un bus unique. La
symétrie est limitée à la mémoire commune.
Elle n'existe plus entre deux processeurs dont l'un peut avoir la donnée
en cache et l'autre la même donnée encore en mémoire.
Il n'y a pas plus de quelques dizaines de processeurs à cause des
limitations des bandes passantes du bus et de la mémoire. Les contenus
des caches privés doivent être maintenus cohérents.
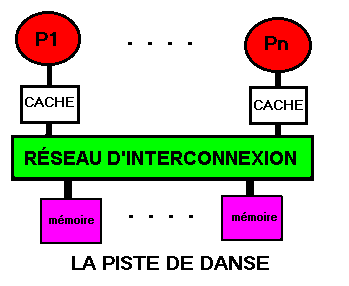
11.6.3 Cache privé
et réseau
Système presque
symétrique.
Ce schéma, comme le suivant, est moins limité que les précédents
en nombre de processeurs car les bandes passantes des réseaux d'interconnexion
«crossbar» et des mémoires en bancs séparés
sont plus grandes que celle du bus unique et de la mémoire unique.
En contrepartie, le temps d'accès à la mémoire est
augmenté et un réseau est toujours plus lent qu'un bon bus
pour une transaction unique.
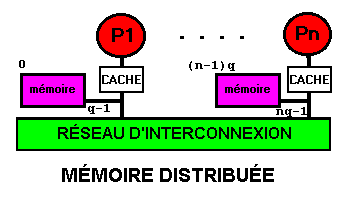
11.6.4 La mémoire
distribuée.
Système asymétrique.
La mémoire demeure commune par le fait que le champ total des adresses
est unique. Par exemple : supposons que les processeurs ont une capacité
d'adressage sur 32 bits et que les bancs de mémoire ont une taille
uniforme de 32 Mo. La mémoire locale du premier sera câblée
de 0 à 32M-1, celle du second de 32M à 65M-1, etc. Les observations
du paragraphe précédent s'appliquent ici, à l'exception
de la distance entre processeurs et mémoire. Cette distance est
courte pour la mémoire attachée à un processeur, elle
est beaucoup plus grande que dans tous les schémas précédents
pour les bancs situés auprès d'autres processeurs.
11.6.5 Petite conclusion
sur mise en commun ou distribution
On résume les éléments
précédents par une deuxième voie de présentation
basée sur partage ou distribution :
La mémoire commune
:
-
a besoin d'un réseau d'interconnexion
coûteux pour être efficace;
-
sinon le nombre de processeurs acceptable
sur un bus est petit;
-
rend facile la programmation;
-
on doit maintenir la cohérence
des données en cas de caches.
L'adressage partagé
:
-
est proche de la mémoire
partagée mais pas identique;
-
l'adressage commun uniformise les
accès;
-
il peut donner lieu à des
systèmes non uniformes.
La mémoire distribuée:
-
nécessite le passage de messages;
-
son matériel est plus facile
à construire ou plus disponible;
-
mais il y a des interruptions entre
processeurs;
-
la programmation est entièrement
à refaire.
La mémoire distribuée
virtuellement partagée:
-
est réalisée par logiciel.
11.6.6
Aperçu sur les questions de cohérence
Au delà de leurs aspects
factuels, les schémas avec plus d'un niveau de mémoire, cache
ou mémoire virtuelle, s'analysent tous en termes de cohérence
(en anglo-saxon «consistency», rarement «coherency»).
Cette cohérence n'a pas de spécification universelle, elle
doit être précisée dans chaque cas particulier. On
fait ici une première présentation du sujet traité
plus loin de façon plus détaillée.
En termes simples la cohérence
concerne les données et les instructions.
-
Les données,
quelle que soit leur nature (données utilisées par un programme,
fichiers, répertoires, etc.). Les données sont cohérentes
si et seulement si à chaque instant, la donnée utilisée
est le résultat de sa dernière mise à jour valide.
Cette validité fait référence au modèle purement
séquentiel.
-
Les instructions.
Elles sont cohérentes si leur exécution fournit le même
résultat que si elles avaient été exécutées
de façon strictement séquentielle.
On trouve dans les deux cas, explicitement
ou non, une référence à la cohérence séquentielle.
Voici les deux situations les plus fréquemment rencontrées.
-
la cohérence des données
a été examinée pour le pipeline et pour les caches
des monoprocesseurs. Il n'y a pas ici
d'ordre spatial initial comme pour les instructions. L'ordre de production
des données est induit par l'ordre des transformations faites par
les instructions. Faute de mieux, il faut s'en remettre, au moins en partie,
au comportement des supports. Dans les multiprocesseurs, on parle volontiers
de cohérence ou de modèles de cohérence de mémoire.
Un modèle de cohérence de mémoire devrait fournir
une spécification formelle du comportement du système de
stockage vu par le programmeur. De nombreux auteurs disent qu'intuitivement
une lecture doit porter sur le résultat de la «dernière»
écriture. Cette intuition n'en est pas une, c'est une habitude prise
depuis longtemps et encouragée par le fait que cette situation est
habituelle dans un monoprocesseur et n'est donc jamais signalée
comme une propriété nécessaire. Cette intuition est
fondée sur l'hypothèse de stricte séquentialité
des productions, conforme à la séquentialité du programme
écrit. Quand cette cohérence que l'on nomme stricte ne va
pas d'elle-même, l'ordre temporel est perturbé par un moyen
spatial. Quand la cohérence n'est pas stricte elle est dite relâchée.
De nombreux processeurs ont des cohérences relâchées,
comme l'Alpha, les SPARC V8 et V9 ou le PowerPC. Hélas, ce n'est
pas toujours la même.
-
la cohérence des instructions
a été présentée pour les pipelines des monoprocesseurs.
On y a vu les moyens de pallier les conflits provenant de l'abandon de
la stricte séquentialité. On a vu l'incidence des interruptions
sur le maintien de la cohérence dans
un pipeline ou plus généralement dans un flot d'instructions.
Ces questions de cohérence surviennent quand l'ordre strict est
perturbé. C'est d'abord un ordre spatial, celui des instructions
se suivant sur un support; c'est un ordre temporel que l'on veut image
du précédent pendant l'exécution. Ce dernier est perturbé
par un moyen spatial le pipeline ou par un événement temporel,
l'interruption.
Autre vision du sujet :
Revenons un instant sur
la façon d'opérer dans un monoprocesseur. Toutes choses égales
par ailleurs, il y a une correspondance dans les deux raisonnements entre
mono et multiprocesseur d'une part et unidimensionnel et multidimensionnel
en mathématiques.
-
Dans l'unidimensionnel ou
dans un monoprocesseur sans pipeline, même s'il fonctionne en multitâche,
il existe un ordre total qui n'est qu'exceptionnellement pris en défaut
au changement de tâche. La rupture d'ordre est alors prise en charge
par le support temporel sous la forme de la sauvegarde et de la restitution
du contexte.
-
En deux ou plusieurs dimensions
ou ici dans un multiprocesseur, cet ordre total n'existe plus. Toutes les
opérations qui se fondaient implicitement sur cet ordre doivent
être traitées précisément.
CE FICHIER N'A PAS
DE QUESTIONNAIRE
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion,
SIMD, MIMD
Année 2002-2003