Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion, SIMD, MIMD
Année 2002-2003
![]() Suite
N°1...
Suite
N°1...
On les nomme souvent machines vectorielles et parfois architectures à données parallèles. Un texte très complet de Krste Asanovic peut être trouvé ici.
Le programme est un flot unique d'instructions strictement séquentiel; il ne contrevient pas aux prescriptions de Neumann.
Ces machines sont exactement
adaptées aux opérations d'algèbre linéaire.
Longtemps leur marché a été le troisième
identifié précédemment. On assiste à une renaissance
du domaine pour le traitement du son, des images et du graphisme, le multimédia.
L'opération banale est de faire construire un tableau somme ou produit
de deux autres :
for i := 1 to n
do a [i] := b [i] + c [i]
Cette suite d'opérations
est traitée en une seule fois pourvu que n
opérateurs d'addition soit utilisables simultanément et qu'ils
aient été alimentés en données. En Fortran
90, on écrira simplement a = b+c.
Le tableau est unidimensionnel
dans le traitement du son, multidimensionnel dans les traitements graphiques.
Ce que nous venons de voir a trait aux seuls processeurs.
L'organisation de la mémoire est autre chose, elle produit deux types de machines vectorielles.
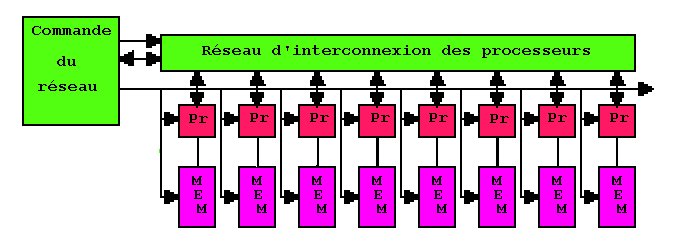
Dans un très grand ordinateur, on trouvera :
Dans les processeurs généraux.
Les algorithmes du multimédia
présentent,
dans un grand nombre de cas, la particularité d'appliquer des opérations
identiques sur un ensemble de données différentes. Des unités
d'extensions multimédia ont été insérées
dans les micro-processeurs récents pour opérer sur plusieurs
données simultanément et de diminuer ainsi le temps d'exécution
de ces programmes. Leur fonctionnement est du type SIMD à registres
comme ci-dessous.
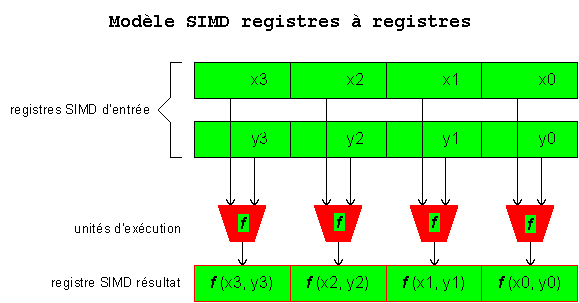
Les registres sont en
petit nombre et découpés en champs selon le type de données.
Une instruction opère sur chacun des champs simultanément
et indépendamment. Il n'y a pas d'interaction entre les champs.
Selon les réalisations, les registres sont de type entier ou flottants,
signés ou non signés, et divisés de multiples façons.
Exemple du MMX d'Intel,
registres de 64 bits entiers. Les fragmentations possibles sont :

Quand le registre est de type flottant (cas du 3DNow! d'AMD et du SSE d'Intel), on trouve des champs de 32 bits (nombre en virgule flottante à simple précision) :

Enfin, la place de ces registres est variable. Les registres SIMD peuvent être des registres pré-existants, on dit qu'ils sont des alias, c'est le cas dans MMX et 3DNow!. Ils peuvent être des registres spéciaux indépendants des autres bancs. C'est le cas du SSE et d'autres processeurs.
Des instructions spécifiques sont nécessaires. Leur nombre varie selon l'architecture SIMD considérée. Hank Dietz de l'université de Purdue en a proposé une classification en 1997.
Opérations
polymorphiques
Les opérations
polymorphiques s'appliquent à la totalité du registre, quel
que soit son partionnement. Ce sont les instructions logiques et, ou, ou
exclusif, la complémentation. L'instruction opère indépendamment
sur chaque bit du registre et produit un résultat de même
longueur.
Opérations
partionnées
Les opérations
partionnées s'appliquent aux champs des registres. Les plus courantes
sont les opérations arithmétiques, addition et multiplication.
Les opérations binaires sont appliquées simultanément
sur tous les champs homologues des registres de départ. Il peut
y avoir interférence. Dans une addition, un bit de retenue peut
déborder vers un autre champ. Pour éliminer ces effets de
bord, on utilise :
- la troncature (wrap around calculation) : on ne prend que la partie significative tenant dans le champ du vecteur résultat (les bits suivants sont perdus);
- la saturation (saturation calculation) : si le résultat obtenu est plus grand (resp. plus petit) que la valeur tenant dans le champ de destination, on y place sa valeur maximale MAX_VALUE (resp. sa valeur minimale MIN_VALUE),
- le re-dimensionnement (packing and promotion calculation) : en réservant le double de l'espace de départ pour le champ d'arrivée, on fait tenir n'importe résultat dans ce dernier quelle que soit la nature de l'opération arithmétique. On ne perd pas de données mais on ne bénéficie plus de la totalité du parallélisme puisqu'on réserve le double de l'espace nécessaire au stockage du résultat. Certains processeurs, comme le MIPS MDMX, ont vecteur d'accumulation de 3 fois la taille des registres SIMD de départ. On peut ici accumuler les résultats de 2n multiplications n x n. Ce type de vecteur est utile pour les multiplications de matrices par exemple.
Opérations
de communication et de conversion de type
Les opérations
de communication déplacent les données entre les divers éléments
de mémoire. Ils proviennent des registres vectoriels comme des registres
classiques, du cache ou de la mémoire centrale.
Les échanges
avec la mémoire gagnent à ce que les données soient
rangées sur une seule ligne pour utiliser la largeur du bus et la
taille de la ligne du cache.
Les mouvements de données
internes à un registre, décalages ou permutations (shift
et shuffle) sont considérés comme des opérations de
communication.
Les conversions de types
sont utilisées pour réorganiser et restructurer l'information
à l'intérieur d'un même registre, ce qui peut impliquer
la contraction ou l'expansion des champs du registre, affectant ainsi leur
taille et leur indexation. Deux cas d'utilisation de ces techniques sont
un partionnement du registre en nouveaux champs de données, ainsi
que la conversion d'un type entier en flottant et vice-versa.
Opérations
de récurrence
Dietz qualifie de récurrentes
les opérations faites par application d'une opération sur
une paire initiale de valeurs puis en la répétant entre le
résultat obtenu précédemment et une nouvelle valeur
jusqu'à épuisement des valeurs d'hypothèse. Ces opérations
peuvent indifféremment produire des valeurs scalaires (qui seront
alors copiées dans chaque champ du registre SIMD) ou non.
Les réductions
associatives sont un exemple d'opération de récurrence retournant
une valeur simple à partir d'un ensemble d'opérandes. Du
fait de leur nature associative, ces opérations peuvent être
exécutées dans un ordre quelconque et sont de bonnes candidates
à la parallélisation. Un cas simple de réduction est
le ou global qui fait le ou logique entre chacun des bits
du vecteur d'opérande et retourne un seul et unique bit de résultat.
Dans ce cas, chaque champ du registre vectoriel est examiné en simultanéité,
l'opération est arrêtée au premier bit à 1 et
le résultat est renvoyé (égal à 1), sinon,
si tous les bits sont à 0, chaque champ est intégralement
parcouru jusqu'à sa fin.
Le gain de performance
est ici variable et dépend de la disposition des bits au sein du
registre. Celui-ci sera d'autant meilleur que le registre sera partagé.
Les particularités SIMD des processeurs généraux sont connues sous des noms divers :
Intel MMX (Multi-Media eXtension)
Cyrix XMMX (eXtended MMX)
AMD 3DNow!
Intel SSE (Streaming SIMD Extension),
anciennement KNI (Katmaï New Instructions) et SSE2 sur 128 bits.
DEC Alpha
HP PA-RISC MAX
SGI MIPS MDMX (MIPS Digital
Media eXtension)
Sun Sparc V9 VIS (Visual Instruction
Set)
Motorola AltiVec
etc...
Les machines vectorielles ne présentent pas de difficultés majeures de conception ou de fonctionnement. La structure de la machine est adaptée à des structures de données. Leur programmation est sans mystère. Le compilateur construit une instruction vectorielle quand il identifie une suite d'opérations identiques portant sur des opérandes indépendants.
Une variante de la machine SIMD est la machine SPMD pour simple programme, multiples données. Le programme est copié en autant d'exemplaires que de processeurs qui ont chacun une mémoire de programme au moins. Le coût additionnel est la présence d'un séquenceur dans chaque processeur et une synchronisation globale.
Dans les années 1970 et
1980 on a vu des machines constituées par des processeurs opérant
sur un seul bit, reliés entre eux de façon à réaliser
une machine de plus grande taille. On faisait alors la distinction entre
les machines parallèles par mot, celle qui traite un mot en une
seule opération et les machines parallèles par bit qui traitent
le bit de même rang de plusieurs mots en une seule opération,
cette distinction est prise en charge dans la taxinomie de Shore.
|
|
pour des données qui ont une structure de tableau à une ou plusieurs dimensions. |
|
Les avantages du vectoriel.
Quelle que soit la structure
du processeur, une machine vectorielle apporte les gains suivants:
.une seule instruction à
lire et décoder pour faire un traitement sur un grand nombre de
données indépendantes (sauf dans les SPMD);
.la disparition de nombreuses
boucles et donc une moindre utilisation du registre de boucle;
.la disparition des tests et
des prédictions de branchements associées quand la taille
du tableau est connue.
Et en plus :
.l'accès simultané
aux registres;
.la possibilité d'exploiter
des bancs de mémoire entrelacés;
.le masquage des temps d'attente
de la mémoire;
.une programmation compacte
qui reste lisible;
.des compilateurs bien connus
et disponibles;
.des performances prévisibles.
Les SIMD les plus marquants ont été (ici processeur est proche d'UAL simple.)
 Ci-contre, un CM-5.
Ci-contre, un CM-5.
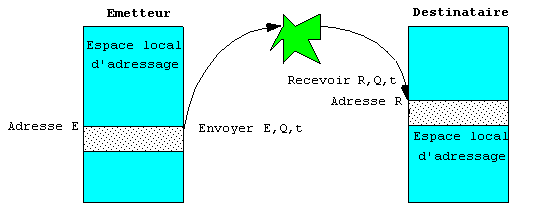
Le modèle de fonctionnement est fondé sur deux ordres ou primitives émettre (send) et recevoir (receive). Chacune a pour argument le nom ou l'adresse implicite ou explicite du destinataire ou de l'émetteur. Le modèle suppose de chaque coté deux tampons temporels de même taille prédéterminée, emplacements fixes de la mémoire locale ou une mémoire ad'hoc. Le contenu du tampon 'mettre est envoyé à l'autre processeur accompagné d'une marque (tag). La primitive de réception le place dans le tampon de réception. Sa lecture ou consommation provoque l'annulation de la marque. La communication se traduit donc par une copie de mémoire à mémoire où chaque extrémité gère l'événement de synchronisation et ses adresses propres. Le mécanisme de synchronisation peut être géré de plusieurs manières.
Ce modèle est utilisé par des langages de programmation, CSP (communicating sequential processes) de T. Hoare, Occam propre aux transputeurs, ainsi que par des outils comme les «sockets» (cavité ou alvéole) d'Unix. Cette cavité est la zone tampon mentionnée plus haut. Attention, le modèle de programmation ne nécessite pas une communication spatiale physique. La primitive émettre peut être traduite par l'écriture du message en mémoire commune, une boite à lettres.
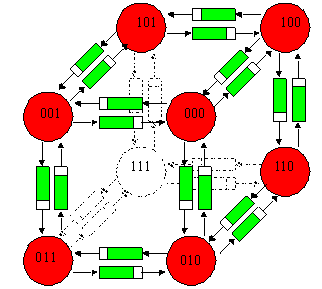
Les plus anciennes réalisations de tels systèmes avaient un schéma fixe d'interconnexion des processeurs comme ILLIAC IV. C'est toujours le cas des hypercubes plus récents ou actuels dont les connexions sont faites dans trois dimensions ou plus. Dans ces systèmes, seuls les voisins immédiats au sens de la topologie d'interconnexion peuvent être immédiatement atteints par un processus.
Le passage synchrone est celui, déjà ancien, où la détection d'arrivée suit immédiatement le début de l'émission, ce qui rend les deux événements synchrones. Les deux processeurs sont bloqués pendant le temps de la transmission. Les langages spécialisés ci-dessus ou les outils des systèmes masquent le mécanisme de transmission pour le programmeur. Le modèle synchrone est figuré ci-après.
Ces mécanismes bloquants ont été remplacés par des mécanismes asynchrones analogues des canaux d'accès direct où l'émetteur comme le récepteur ne sont pas bloqués pendant la durée de la transmission. On retrouvera cette opposition entre synchrone et asynchrone dans la conclusion.
L'étape suivante a consisté à augmenter la qualité (et non le contenu) du message qui peut être émis librement vers un processeur quelconque. Une couche de communication câblée ou programmée prend en charge le routage du message dans le réseau. La primitive recevoir fait son affaire de l'écriture du message chez le destinataire.
Modèle abstrait de communication simple par message :
Exemple de communication entre voisins dans un cube par files d'attente :
Des machines comme l'IBM SP2 et l'Intel Paragon, affectent un processeur à la gestion des communications.
Dans une machine à communication de messages :
![]()
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 11
Types de communications, topologies de connexion,
SIMD, MIMD
Année 2002-2003
![]()
![]()