Architectures des systèmes informatiques
CHAPITRE 10
Parallélisme, taxinomies et classifications
Année 2002-2003
![]() Suite
N°3...
Suite
N°3...
10.4.3 La classification de Handler
La classification de W. Handler a été publiée en 1977. Son objectif est de préciser le pipeline et le parallélisme des structures. L'ordinateur est observé sous trois espèces :
Ordinateur = (k * k', d * d', w * w')
Les règles et les opérateurs suivants sont utilisés pour monter les liens entre les différents éléments d'un ordinateur.
L'opérateur * est utilisé pour indiquer que les unités sont en pipe line ou macro pipeline avec un flot de données unique à travers toutes les unités.
L'opérateur + est utilisé pour indiquer que les unités ne sont pas en pipeline mais travaillent sur des flots de données indépendants ou séparés
Ces opérateurs sont utilisés pour assembler des matériels différents.
L'opérateur V est utilisé pour indiquer que le matériel peut travailler dans un mode parmi plusieurs. Il combine des descriptions du même matériel, c'est un OU.
Le symbole ~ est utilisé pour indiquer un jeu de valeurs pour un des paramètres.
Les processeurs périphériques sont présentés avant le processeur principal. On utilise pour eux, trois autres paires d'entiers. Si la valeur du second élément d'une paire est 1, il est omis pour faire court.
Voyons ce qui en résulte sur quelques exemples :
Exemple 1, CDC
6600.
Il a un processeur central unique
, son unité de commande de type pipeline commande une UAL à
10 unités fonctionnelles indépendantes dont les mots sont
de 60 bits. Il a 10 processeurs périphériques d'entrée
et sortie qui peuvent simultanément entre eux et avec le processeur
central. Chaque processeur d'entrée-sortie contient une UAL simple
sur 12 bits.
Les processeurs d'entrée et sortie sont décrits par :
CDC 6600 = (10, 1, 12) * (1, 1 * 10, 60)
Exemple 2, Advanced Scientific
Computer (ASC).
Cette machine de Texas Instrument
a une unité de commande pour quatre unités arithmétiques.
Chacune d'elles a un pipeline à huit étages sur des mots
de 64 bits. On obtient alors :
Exemple 3, Cray-1.
C'est un monoprocesseur de 64
bits. Son UAL a 12 unités fonctionnelles, huit d'entre elles peuvent
être chaînées pour former un pipeline. Différentes
unités fonctionnelles ont de 1 à 14 segments qui peuvent
être mis en pipeline.
La description de Handler pour
le Cray-1 est :
Cray-1 = (1, 12 * 8, 64 * (1 ~ 14))
Exemple 4, C.mmp.
Cette machine très aisément
reconfigurable a été mentionnée. Elle consiste en
16 PDP-11, mini ordinateurs des années 70, à mots ont 16
bits. Ils sont interconnectés par un réseau de type «crossbar».
Normalement, le C.mmp travaille
en mode MIMD, sa description est alors (16, 1, 16).
Il peut aussi travailler en mode SIMD, où tous les processeurs sont coordonnés par un seul contrôleur maître, sa description est alors (1, 16, 16).
Enfin, le système peut être réorganisé pour travailler en mode MISD. Les processeurs sont alors chaînés. Un seul flot de données les traverse tous, sa description est alors (1 * 16, 1, 16).
La description de Handler pour le C.mmp complet est alors :
Exemple 5, DAP.
Le «distributed array
of processors» d'ICL est lui aussi reconfigurable. C'est un ensemble
de processeurs de bits organisés en treillis avec une seule unité
de commande. Il peut travailler comme un ensemble de 128 UAL de 32 bits
avec 64 kbits de mémoire. Par reconfiguration il devient un ordinateur
avec 4.096 UAL de 1 bit et 4 kbits de mémoire. À ses débuts,
il devait être machine frontale d'un ICL 2900 dont la description
est (1, 1, 32). Le DAP était construit pour ressembler à
un bloc de mémoire de 2 Moctets vu par un ICL 2900.
Le lecteur s'est rendu compte que Handler a fait évoluer l'appartenance à une classe vers une sorte de résumé descriptif.
Shore l'a proposée en 1973. Elle est fondée sur la structure et le nombre des unités fonctionnelles de l'ordinateur. Elle a six classes chacune désignée par un chiffre romain.
Type I
L'ordinateur série classique de Neumann appartient à la catégorie I, identique au SISD de Flynn. Une seule unité de commande est consacrée à une ou plusieurs unités fonctionnelles. Les ordinateurs vectoriels relèvent donc de cette classe eux aussi, même avec pipeline. Le processeur travaille sur des mots de mémoire, il est dit mot-série, bits-parallèle. Les CDC 7600 et Cray-1 sont de ce type.
Type II
Les machines de cette classe sont semblables à celles du type I à part le fait qu'elles travaillent sur des tranches de bits (vertical slices) de la mémoire, plutôt que sur des mots (horizontal slices). Le processeur travaille en mot-parallèle, bit-série. Deux exemples sont le DAP d'ICL et STARAN de Goodyear Aerospace.
Type III
Les machines de cette classe sont des combinaisons des types I et II. Une machine de type III a deux unités de traitement, une travaillant sur des mots de données, l'autre sur des tranches de données.
Le DAP et le STARAN peuvent être programmés ainsi. Toutefois, ils le font dans la même unité de traitement et donc pas de façon simultanée, ils ne sont donc pas proprement de ce type. Les OMEN-60 de Sanders Associates appartient à cette catégorie.
Type IV
Les machines de type IV sont semblables au type I, sauf que l'unité de traitement et la mémoire sont doublées. La communication entre les processeurs ne peut se faire que par l'unité de commande.
La machine est facile à étendre par addition de processeurs. La bande passante est limitée par le fait que tous les messages passent par l'unité de commande. Les machines de cette classe peuvent être nommées : réseaux non connectés. Un exemple est PEPE.
Type V
Les machines de cette classe sont semblables à celles du type IV, sauf que les processeurs sont organisés en chaîne. Chaque processeur peut adresser la mémoire de ses voisins directs. Un exemple est ILLIAC IV. D'autres communications existaient dans ILLIAC IV. Ces machines sont parfois appelées réseaux connectés.
Type VI
Les cinq premiers types ont des unités de traitement distinctes et des mémoires interconnectées par bus ou par réseau à commutation. La classe finale de machines identifiées par Shore est constituée de machines dont la mémoire porte une partie de la logique : «Logic in memory array» ou LIMA.
Les mémoires associatives simples et les processeurs associatifs complexes sont de ce type.
Commentaire
Cette taxinomie a passablement vieilli. Les machines travaillant sur un bit ou sur des tranches de bits verticales ont disparu. Cette taxinomie cédait à la mode et n'avait pas de vision prospective.
10.4.5 La méthode de Hockney and Jesshope
Hockney et Jesshope ont présenté une notation compliquée en 1988, appelée notation structurelle de type algébrique (algebraic-style structural notation ou ASN) pour décrire les ordinateurs parallèles.
Elle serait particulièrement longue à exposer en détail. La taxinomie proprement dite est constituée de plusieurs arbres dont les nuds contiennent des annotations algébriques. Une machine installée sur un nud sera décrite par la chaîne de descripteurs obtenue en collectant les annotations à partir de la racine jusqu'au nud en cause.
Illustrons simplement cette méthode par la description du Cray I :
C(Cray-1) = Iv12[12Ep12 - 16M50]r; 12Ep = {3Fp64,9B}
On n'a plus une définition
de classes, mais une description abrégée de la machine en
cause.
La ligne ci-dessus se lit pour
un spécialiste de la chose :
«une
unité d'exécution non pipeline avec une horloge de 12 ns.
Une unité d'exécution en pipe line à 12 étages,
horloge à 12 ns, connectée à 16 bancs de mémoire
dont le temps d'accès est de 50 ns. Les instructions sont émises
quand l'unité d'exécution et les registres sont libres. Les
douze unités d'exécution sont constituées de 3 pipelines
arithmétiques en virgule flottante 64 bits qui peuvent travailler
en parallèle avec neuf unités entières non pipeline.»
Le résultat pour chaque machine est un descripteur encore plus complexe que celui de Handler.
On trouve cette méthode dans l'ouvrage des auteurs [HOC88].
10.4.6 Conclusion sur les taxinomies
Il en est des taxinomies comme des normes, certaines sont utilisées, d'autres ne le sont pas. Actuellement, la taxinomie de Flynn est utilisée pour distinguer les SIMD des MIMD. Les MIMD font l'objet de distinctions sur d'autres bases.
10.5 LA CLASSIFICATION ACTUELLE DES MIMD
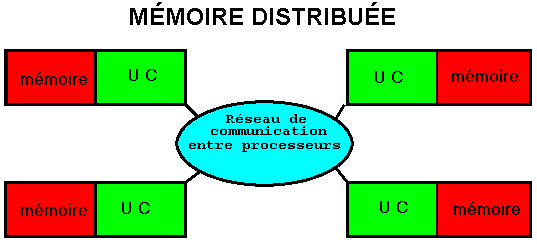
Elle est fondée sur la nature du moyen de communication entre les processeurs :
Une autre dénomination est système à accès non uniforme (NUMA pour «non uniform memory access»).
Chacun des processeurs a sa propre
mémoire, un bus ordinaire y suffit.
La communication entre
les processeurs est faite par messages.
Variantes
Systèmes à mémoire distribuée virtuellement.
La distribution est faite
par logiciel dans la mémoire commune (sauf dans le KSR).
Le modèle de
programmation classique est conservé.
Le système de
communication est ici aussi primordial.
Exemples : KSR, DASH,
Alliant...
Systèmes à hiérarchies de mémoires.
On y combine la mémoires partagée entre un groupe de processeurs et plusieurs groupes communicant via une grande mémoire.
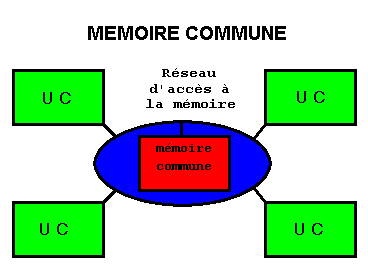
10.5.2 Machines à communication temporelle, mémoire commune aux processeurs
Une autre dénomination
est système à accès uniforme (UMA pour «uniform
memory access»).
Les processeurs ont la même
mémoire et y ont accès chacun dans le même délai,
notion d'uniformité.
Il y a bien sur un moyen de communication entre les processeurs et la mémoire, mais il ne s'agit pas ici du moyen sur lequel est fondé le classement. On utilise des bus dans les SGI, DEC, SUN... et des commutateurs dans les CRAY, FUJITSU, NEC...
Selon l'implantation du système d'exploitation et des programmes, on distingue les multiprocesseurs :
Intel a mis en service en 2002 sur le Xéon, une technique nommée «hyper threading» qui consiste à émuler deux processeurs sur un seul. On peut en rendre compte de deux façons :
10.6 CARACTÈRES DU PARALLÉLISME
On récapitule ici plusieurs caractères par lesquels on trie, on classe (mal), on étiquette des machines parallèles ou des fonctionnements simultanés :
Le degré au sens du nombre de travaux que l'on peut exécuter simultanément tâches, miniprocessus, etc.
La granularité au sens de la quantité moyenne de travail incorporée dans chaque travail élémentaire, grain fin (fine grain) pour des tâches petites, grain grossier (coarse grain) pour des tâches grandes.
Le niveau au sens de l'origine de la simultanéité :
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 10
Parallélisme, taxinomies et classifications
Année 2002-2003
![]()
![]()