Architectures des systèmes informatiques
CHAPITRE 6
Mémoires de masse
Année 2002-2003
![]() Suite
N°4...
Suite
N°4...
6.7 LES DISQUES RAID ou RÉSEAUX DE DISQUES
6.7.1. Pannes et sensibilité, notion de tolérance
Les ordinateurs sont très sensibles aux pannes et aux défauts de fonctionnement. Ils contiennent un nombre considérable de composants qui, même fiables ont des pannes. Le couplage des ordinateurs à d'autres systèmes et le caractère indispensable de leur travail dans de nombreuses activités ont conduit à essayer de les rendre insensibles aux pannes ou tolérants aux pannes selon la traduction mot-à-mot des informaticiens (fault tolerant), ou au moins à faire en sorte qu'une panne n'ait pas de conséquence dommageable.
Les défauts de fonctionnement proviennent pannes de composants aussi des erreurs des opérateurs, des perturbations radioélectriques, des variations de températures, des chocs subis, les erreurs dans les logiciels, etc. Dans tout cela, la séparation des responsabilités entre le matériel et le logiciel est estompée pour un utilisateur qui ne veut savoir qu'une chose : «Mon système fonctionne bien».
Par ailleurs l'augmentation de la fiabilité et la diminution de la durée d'utilisation par une obsolescence technique rapide, font que l'observation répétitive de pannes matérielles devient rare. Il n'y a plus l'accoutumance traditionnelle à la panne d'un système matériel connu et utilisé pendant de très nombreuses années. Au début du siècle, le premier geste enseigné à un acheteur d'automobile était le changement des bougies et le nettoyage du carburateur. Un mécanicien connaissait par expérience les points faibles de sa machine. L'automobiliste moyen d'aujourd'hui sait-il encore qu'il y a des bougies dans un moteur ? Le mécanicien fait-il autre chose que l'échange de pièce ?
Nous ne pouvons pas examiner dans ce chapitre les machines dites communément «à tolérance de pannes», un cours entier n'y suffirait pas eu égard aux particularités architecturales et aux considérations mathématiques indispensables.
6.7.2 Défauts, erreurs, comportements fautifs etc.
Leurs manifestations relèvent :
.de la panne, terme général, elle apparaît quand le service fourni est différent de celui qu'il aurait dû être;Les caractères temporels en sont :
.du défaut, il s'agit d'un état incorrect dû à une panne de composant, à une interférence avec une condition d'environnement, une erreur d'action d'un opérateur, ou enfin d'une construction fautive;
.de l'erreur, c'est la manifestation du défaut dans l'exécution d'un programme ou dans une donnée. Elle n'est pas nécessairement immédiate ni visiblement reliée à la faute.
.la permanence, le défaut, la faute, la panne sont stables et répétitifs;Les attitudes possibles sont :
.l'intermittence, le défaut ou l'erreur ne sont présents que de façon occasionnelle;
.le transitoire, le défaut ou la panne, est présent une fois et n'apparaît plus pendant la période d'observation qui suit.
.le confinement du défaut, on essaye de limiter le champ d'application du défaut en le confinant au mieux;QUELQUES MESURES UTILISÉESMTBF temps moyen entre pannes «mean time between failure»;
.le masquage du défaut, on fait en sorte que le défaut s'il existe n'est pas perceptible; on peut utiliser des composants supplémentaires à l'identique; la décision majoritaire entre trois circuits, par exemple, masque le fait que l'un d'eux est en défaut;
.l'itération ou essayer à nouveau, cette technique est efficace pour les disques;
.le secours, en cas d'erreur détectée et localisée, on commute sur un équipement qui était en attente;
.la reconfiguration, un défaut étant détecté et localisé, le système se «reconfigure», c'est à dire isole la partie défaillante et continue à fonctionner en utilisant soit un organe de secours ad'hoc, soit des parties ou des manières d'opérer différentes de telle sorte que le résultat correct soit obtenu, fût-ce au prix d'une baisse des performances; le système est alors dit fonctionner en mode dégradé;
.la reprise, en cas de défaut corrigé ou de système reconfiguré, il y a lieu de faire une «reprise après panne», c'est à dire de reprendre l'exécution à partir d'un état encore intègre, qui précédait bien sûr l'apparition du défaut;
.le redémarrage à chaud est une reprise au point d'erreur s'il n'a pas causé de perturbations;
.le redémarrage à froid est la solution ultime où l'on recommence tout si c'est possible;
.la réparation, si elle est faite hors ligne, il s'agit de la réparation classique; si elle est prévue en ligne, il s'agit, manuellement cette fois, soit de l'équivalent d'une reconfiguration, soit d'une réparation classique; la seule différence est que le système n'a pas été arrêté.
Les trois catégories principales de techniques sont :
La détection des erreurs n'apporte pas d'insensibilité stricto sensu, elle fait partie de ces techniques en tant qu'elle provoque une alarme, préférable à un comportement fautif ignoré.
Le masquage par redondance utilise des composants matériels ou logiciels à , non pas pour éviter qu'une panne se produise mais pour faire qu'elle soit sans effet. Cela est fait par codage correcteur d'erreurs, par duplication et surtout par triplication; le résultat retenu à la sortie des trois composants identiques est choisi par décision majoritaire.
La redondance dynamique. Lorsqu'une erreur est détectée, le système est reconfiguré par un opérateur ou encore par lui-même. Cette technique n'est pas exclusive des deux précédentes, elle les complète.6.7.3 Exemples
| Type d'usage | Base | Technique | Exemples | en |
| Général | monoprocesseur | détection | Univac
I
DEC VAX IBM3090 |
1951
1979 1985 |
| Disponibilité | multiordinateur | secours | IBM
Sage
ATT 3B20D |
1958
1981 |
| dynamique | Tandem
Stratus |
1978
1981 |
||
| multiprocesseur | dynamique | Intel
432
Sequoia |
1982
1986 |
|
| Calculs critiques | monoprocesseur | masquage | Spécifique
pour la fusée Saturn V
C.vmp FTP |
1968
1977 1988 |
| multiordinateur | masquage | Spécifique
pour la navette spatiale
SIFT |
1977
1979 |
|
| Durée de vie | monoprocesseur | masquage | Star | 1969 |
| multiordinateur | secours | Spécifiques
pour la sonde Voyager
pour la sonde Galilée |
1978
1989 |
L'Univac I date de 1951. Il fut le premier ordinateur commercial à contenir des dispositifs qui nous intéressent encore bien qu'ils n'aient pas vraiment fonctionné. Toutes les cinq secondes, le processus en cours devait être arrêté et une vérification de la mémoire faite par calcul de parité. Le flot de commande était accompagné de bits de parité. Les unités arithmétiques ainsi que les registres étaient dupliqués. Une erreur sur la comparaison des résultats devait arrêter le fonctionnement.
L'ATT3B20D est un ordinateur de 1981 pour la commutation téléphonique. Son objectif était, en terme de disponibilité, de 2 heures de panne pour 40 ans de fonctionnement, soit 3 minutes par an en moyenne. Toutes ses fonctions étaient dupliquées y compris la mémoire et les disques montés en miroir. Dès une détection d'erreur, le système d'exploitation consultait une base de données pour trouver la nouvelle configuration optimale.
Les machines de Tandem étaient composées de 2 à 16 ordinateurs, chacun disposant de sa mémoire, de ses entrées sorties et de sa propre alimentation. Ils étaient interconnectés par l'intermédiaire de deux machines spécialisées pour la commutation de messages nommées Dynabus. Cette idée est reprise dans le projet de norme d'interface SCI IEEE P1596.
Stratus Computers a commencé ses productions en 1980. Ses machines étaient basées sur des microprocesseurs. L'objectif était un fonctionnement ininterrompu, sans perte d'information et sans dégradation de performances. Pour cela une vérification était faite en permanence entre des éléments dupliqués. La démonstration du «bon fonctionnement» en cas de panne était faite en enlevant successivement des cartes sans résultat visible sur l'évolution du processus en cours. Les machines Stratus étaient commercialisées en France par Logabax.
6.7.4 Les RAID
Au début RAID était
le sigle de :
«Redundant Array of Inexpensive
Disks»
Aujourd'hui on l'entend comme
:
«Redundant Array of Independant
Disks»
Cette invention est due à Randy Katz de Berkeley à la fin des années 80 [KAT88]. Son équipe universitaire a défini une échelle à cinq barreaux (1 à 5) pour définir des assemblages de disques travaillant à l'unisson de telle sorte qu'ils se comportent comme un seul disque, tout ceci est sous la commande d'un contrôleur ou d'un logiciel adéquat. L'objectif principal était et reste la sûreté du stockage de l'information plus que l'économie sur le coût total des disques. Les niveaux 0 et 6 ont été ajoutés ultérieurement.
En 1989, Thinking Machines Corporation annonçait DataVault un sous système de stockage constitué de 84 petits disques.
Note :La signification initiale de RAID peut conduire à une controverse sur les coûts relatifs d'une même capacité de stockage en un grand disque ou plusieurs petits. Ce n'est pas le sujet et cela ne l'a jamais vraiment été. Il ne faut pas raisonner sur le prix mais sur deux autres paramètres qui sont la fiabilité et le débit que l'on obtient des petits disques au moyen de la technique RAID et celle que le grand disque de capacité égale devrait avoir.
La littérature disponible ne met pas souvent ces notions au clair. Le lecteur peut constater qu'après une introduction relative à la meilleure fiabilité apportée par la technique RAID, les développements comparent très systématiquement les performances en temps d'accès et en débit, sans plus se préoccuper de la fiabilité de l'ensemble. Remarquons de plus que petit disque et grand disque ne sont pas des notions absolues.
Un disque RAID est un groupe de disques qui apparaît aux processus comme un disque logique unique. C'est l'opposé de ce que l'on fait par la technique de la partition.
Dans les réalisations opérationnelles, on veut pouvoir accepter qu'un disque soit inaccessible, les opérations se passent comme suit. Il y a d'abord détection nécessaire du disque fautif (en principe par le contrôleur). Le travail est poursuivi en utilisant soit un doublon, soit, au prix d'un ralentissement, en calculant les informations perdues. Dès que le disque remplaçant est disponible, soit parcequ'il est déjà monté soit parce le disque fautif est changé, le processus de régénération de ses données est lancé. Le cas échéant on répare le disque fautif qui devient le nouveau disque de rechange.
Caractéristiques détaillées
Dans les explications qui suivent :
A, B, C..., a, b, c... sont des éléments successifs du fichier : bloc, octet, bit.
1, 2, 3... sont les portions successives d'un même disque que l'on trouve sur chacun des disques, ce sont les emplacements homologues.
Les dimensions de A, B... ou de a, b... sont identiques à celles de 1, 2...
Par panne, on entend tout événement qui empêche l'accès correct à des données. Le nombre de disques choisis dans les figures suivantes est arbitraire. Sauf autre spécification, la parité se calcule par OU exclusif (XOR) sur l'ensemble des positions de même rang.
Les caractéristiques ci-après peuvent différer selon la réalisation en termes de type, de coût, de performance des lectures et écritures, de fiabilité, de nombre, de type et de performances des contrôleurs, de la présence et de la taille d'un cache dans le contrôleur, etc. Il ne faut pas oublier que la fiabilité est celle de la chaîne complète qui inclut l'alimentation, le contrôleur, les liaisons ou canaux, etc. La meilleure disponibilité nécessite le doublement des alimentations, des contrôleurs, des canaux, des accès croisés, etc.
Niveau 0 ou R0 ou RAID 0
Il a été ajouté
après coup à la classification initiale par des industriels.
Il n'y a pas de redondance, seuls des CRC attachés aux secteurs
détectent des erreurs. On pourrait le nommer AID. Un seul disque
est un disque banal. Si l'on a plusieurs disques à accès
simultané, un découpage de l'information (stripping)
est fait selon la figure ci-dessous. Si chaque enregistrement unitaire
est plus petit ou égal à une zone de couleur, chaque transaction
ne concerne qu'un disque. Les taux de transfert sont ceux d'un seul disque.
Ils sont plus grands si la taille des enregistrements est plus grande.
Les tranches de fichier A, B, C... sont lues ou écrites simultanément
sur les disques. Plusieurs transactions peuvent être enregistrées
simultanément sur plusieurs disques. La capacité des disques
est utilisée à 100 % pour les données. Le rapport
volume stocké/coût est bon.

Niveau 1, R1
Il est le premier du document
de Berkeley. La même information est lue sur un seul disque et écrite
simultanément sur 2 disques. Il y a duplication ou
disque miroir
(mirroring ou shadowing). La capacité totale des disques est utilisée
à 50%. Les performances sont celles du disque isolé en lecture
puisqu'on n'en lit qu'un. Elles sont moins bonnes en écriture qui
est faite deux fois. Cette technique est utilisée communément
depuis les années 60.
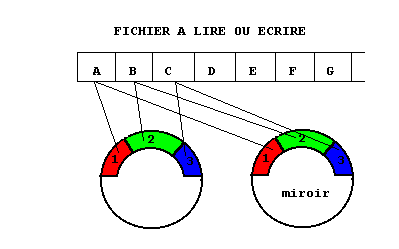
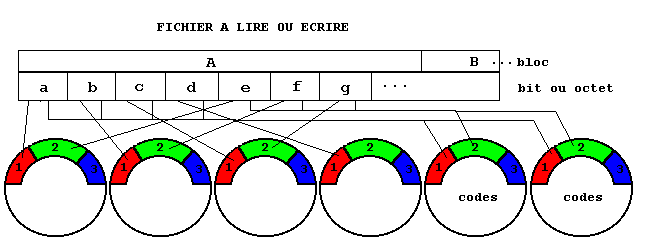
Niveau 2, R2
Les données sont groupées
en blocs comme dans le niveau 0. Les bits ou les octets successifs d'un
bloc sont écrits sur des disques différents. Un code détecteur
et correcteur d'erreurs est calculé sur le bloc, en général
un code de Hamming. Il est écrit sur deux ou plusieurs disques dits
de redondance. En cas d'une seule erreur dans le bloc, l'exploitation
du code fournit à la fois le numéro du disque fautif et la
valeur reconstituée. En cas de deux erreurs, le calcul ne fait que
détecter les erreurs. Ce niveau a été inventé
alors que les contrôleurs ne détectaient pas le disque fautif.
Les disques sont utilisés aux deux tiers environ pour les données,
ce qui est meilleur que dans le niveau
1. Il est pratiquement abandonné au profit du niveau 3.
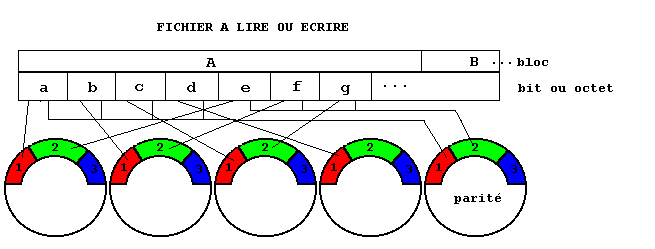
Niveau 3, R3
Les bits successifs d'un bloc sont écrits sur des disques différents. Ici, les contrôleurs sont supposés capables de détecter quel disque est en panne. Il n'est plus besoin de code détecteur d'erreur. Si l'on s'en tient à la correction d'une seule erreur, un bit de parité suffit. Les bits de parité sont stockés sur un seul disque.
Dans l'exemple de la
figure ci-dessous, les disques sont utilisés à 80%. Le nombre
des entrées et sorties est limité par le fait tous les disques
sont actifs simultanément et de manière synchrone. Il ne
peut y avoir qu'un accès logique à un instant donné.
Le dernier disque, ici le 5e, contient dans sa position i la parité
des positions i des quatre disques de données. Les tailles de a,
b... sont ici aussi très petites, de l'ordre du bit ou de l'octet.
En cas de panne d'un disque de données ou de parité, identifiée
par un contrôleur, l'information est reconstruite à partir
des autres disques. Après la réparation ou pendant la réparation
s'il y a un disque de réserve, le contenu du disque erroné
est reconstruit. Le système est indisponible en cas de panne simultanée
de 2 disques. Il est très efficace pour des entrées et sorties
séquentielles de grands fichiers. Il est peu efficace pour des entrées
et sorties nombreuses et aléatoires car le disque de parité
est sollicité pour chaque accès.
Emploi de la parité,
code de Reed-Solomon élémentaire.
Elle consiste
à construire un bit comme résultat du OU exclusif (XOR) de
tous les bits considérés. Ceci est équivalent à
dire : si la somme des bits est paire, le code vaut 0, si elle est impaire,
le code vaut 1. Ainsi l'ensemble séquence plus code est toujours
pair.
Soit à écrire la suite : 0110111011110111, les bits vont être écrits successivement sur les disques, lire de haut en bas et de droite à gauche :
disque 1 : 0110
disque 2 : 1111
disque 3 : 1111
disque 4 : 0011
disque de parité
numéro 1 : 0 XOR 1 XOR 1 XOR 0 = 0
1 XOR 1 XOR 1 XOR 0 =
1
1 XOR 1 XOR 1 XOR 1
= 0
0 XOR 1 XOR 1 XOR 1
= 1
Processus de reconstitution, on fait la suite des XOR sur les bits conservés et sur le bit de parité. Supposons endommagé le disque 4, la séquence XYZT sera reconstituée par :
X = 0 XOR 1 XOR 1 XOR
0 = 0
Y = 1 XOR 1 XOR 1 XOR
1 = 0
Z = 1 XOR 1 XOR 1 XOR
0 = 1
T = 0 XOR 1 XOR 1 XOR
1 = 1
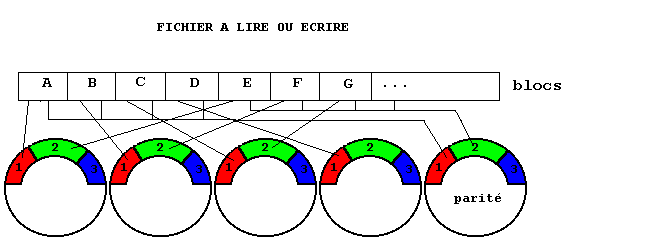
Niveau 4, R4
Il est analogue au niveau 3 avec
une différence. Chaque bloc (le
plus souvent un secteur) et non des bits
ou octets successifs d'un bloc, est écrit sur un seul disque. Les
bits de parité sont calculés sur les bits homologues des
blocs successifs. On retrouve l'avantage initial de la lecture d'un bloc
en un seul accès sur un seul disque. Comme dans le niveau 3, le
disque qui contient les bits de parité est sollicité à
chaque accès.
À coût
égal, la performance de ce niveau est moindre que celle de R5, il
n'est donc pas utilisé.
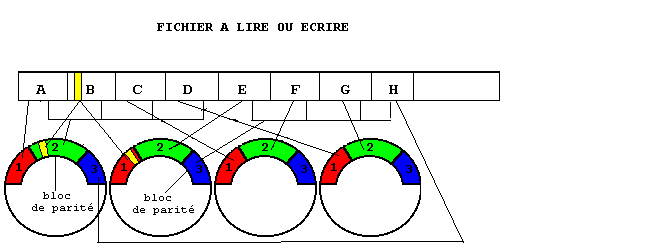
Niveau 5, R5
Il est analogue au niveau 4 avec une différence. Les bits de parité ne sont pas écrits sur un disque réservé mais entrelacés avec les données selon des algorithmes de placement variés. Selon le placement, on s'approche des performances des disques miroirs.
Dans l'exemple présenté, l'utilisation des disques est de 80 %. Le bloc de parité des blocs de données A, B, C et D est écrit dans le premier emplacement libre, le n° 2 du disque A. L'écriture des blocs de données est poursuivie dans les emplacements libres. Les blocs sont grands comme en R4.
La réécriture
d'un petit enregistrement (jaune) implique la lecture du bloc qui contient
l'ancienne valeur et du bloc qui contient sa parité pour le mettre
à jour, puis une écriture sur chaque disque. En cas de panne
d'un disque, il est toujours nécessaire de lire tous les blocs sur
tous les disques restants pour reconstruire l'information perdue. La solution
est bien adaptée à de nombreuses transactions de petites
tailles, surtout en lecture (rapport écriture/lecture petit).
Niveau 6, R6
Il a été ajouté par des industriels et des universitaires au système de Berkeley. Il peut différer de l'un à l'autre.
Certains auteurs remplacent le bit de parité par un code de Reed-Solomon plus volumineux. Il détecte deux erreurs et en corrige une. Cette technique est connue depuis 1971. Le nombre de disques en est augmenté mais la panne simultanée de deux disques est acceptée.
D'autres auteurs utilisent deux codes simultanés pour accepter la panne simultanée de 2 disques. Les volumes de deux disques de parité sont alors nécessaires ainsi qu'un traitement plus complexe des données. Les informations de parité sont ou non réparties sur l'ensemble des disques. La société StorageTek propose la matrice de disques Iceberg dans cette technique.
IBM donne une toute autre définition d'un système RAID 6 (ou HYBRID RAID 1). Ce système est basé sur une configuration RAID 1. La copie des informations contenues dans le segment numéro 1 est située sur le segment numéro 2, mais décalée d'un disque vers la droite.
En résumé le but
visé est l'équilibre de la première figure :

R0 fournit :
R1 fournit :
R3 et R5 fournissent :

R3 a sa meilleure performance
en débit pour de gros fichiers séquentiels
R5 a sa meilleure performance
en nombre d'entrées et sorties, s'il n'y a pas beaucoup d'écritures.
R6 a la meilleure disponibilité
pour un prix plus élevé.
L'auteur est grandement redevable à Michel Jaunin de l'Ecole Polytechnique Fédérale de Lausanne pour ce paragraphe.
6.7.5 Récapitulation
comparative
| CARACTÉRISTIQUE | RAID 1 | RAID 2 | RAID 3 | RAID 4 | RAID 5 | ||
| PRIX | élevé | élevé | moyen | moyen | moyen | ||
| REDONDANCE |
50%
|
> 33%
|
< 33%
|
< 33%
|
< 33%
|
||
| NOMBRE DE PANNES TOLÉRÉES | autant que de miroirs | autant que de disques de redondance | une au plus | une au plus | une au plus | ||
| TECHNIQUE | miroir | code de Hamming | parité
sur un disque |
parité
sur un disque |
parité distribuée | ||
| SYNCHRONISATION des disques | non | oui | oui | non | non | ||
| REMPLACEMENT À CHAUD | oui | non | non | non | oui | ||
| LONGUEUR DE L'ENREGISTREMENT | bit ou bloc | bit | bit | bloc | bloc | ||
| LECTURES ou ÉCRITURES SIMULTANÉES |
|
|
|
|
|
||
| SÉCURITÉ | très forte | forte | moyenne | moyenne | moyenne | ||
| COMPARAISON |
< au RAID 3
|
< au RAID 5
|
|||||
| RECOMMANDATION | tous usages | grands fichiers | grands fichiers | transactions | transactions | ||
![]()
Conservatoire national des arts et métiers
Architectures des systèmes informatiques
CHAPITRE 6
Mémoires de masse
Année 2002-2003
![]()
![]()